
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- initial-exec
- Linux custom packer
- on-stack replacement
- Injection
- uftrace
- linux debugging
- linux thread
- Android
- android inject
- v8 tracing
- so inject
- LLVM Obfuscator
- pthread
- v8 optimizing
- on stack replacement
- apm
- TLS
- Obfuscator
- thread local storage
- Linux packer
- LLVM 난독화
- OSR
- tracerpid
- tracing
- 안티디버깅
- anti debugging
- custom packer
- 난독화
- LLVM
- pinpoint
- Today
- Total
Why should I know this?
LLVM 최적화 패치 제출까지의 순서 정리 본문
https://die4taoam.tistory.com/122
LLVM 에 패치 보내기 튜토리얼
https://youtu.be/C5Y977rLqpw?si=JXvJ7RsQ-26XSW4i 패치 만들고 LLVM 에 보내기 코드를 수정한 뒤 LLVM 에 기여하는 방식은 code-review 과정을 별도의 플랫폼에서 거친다는 차이가 있습니다. 이에 대한 자세한 과정
die4taoam.tistory.com
LLVM에 패치 보내는 튜터리얼은, Nikita Popov 가 작성한 글을 기반으로 작성됐습니다. 현재는 이 글에 포함되어 있는 리뷰과정은 모두 완전 github로 옮겨간 점 등이 달라졌으며, github 환경에 익숙한 사람들에게는 오히려 더 쉽게 LLVM에 기여할 수 있는 기회가 될 수 있을 것 같습니다.
이런저런 경험을 하면서, 당시에 가장 적합한 경험과 지식을 기반으로 비슷한 입장에 있는 사람들에게 도움이 되는 글을 남기고자 하는 목적으로 기록을 남깁니다.
1. middle-end 최적화에 참여하는 방법?
가장 쉬운 방법은 github llvm issue에 등록된 이슈 중에 뒤지는 것 입니다.
https://github.com/llvm/llvm-project/issues/71792
Simplification Comparison for `(a | b) ? (a ^ b) : (a & b)` etc. (Clang13 vs Clang trunk) · Issue #71792 · llvm/llvm-project
Consider the following six functions. https://godbolt.org/z/cTsd43jhh bool test1(bool a, bool b) { return (a | b) ? (a ^ b) : (a & b); } bool test2(bool a, bool b) { return (a | b) ? (a & b) : (a ^...
github.com
이 이슈처럼 이런 최적화가 가능할 것 같다. 라는 식으로 이슈를 올리는 사람이 있으니 이런걸 뒤져서 할만한걸 찾으시면 되고, 아니면 good first issue 로 라벨링 된 이슈 중에 찾으셔도 됩니다.
https://github.com/llvm/llvm-project/issues/33874
Improve bitfield arithmetic · Issue #33874 · llvm/llvm-project
Bugzilla Link 34526 Version trunk OS Windows NT CC @alexey-bataev,@legrosbuffle,@rotateright Extended Description We could improve math ops on irregular bitfields with the relevant SWAR style patte...
github.com
2. middle-end 최적화 만들고 검증하기
middle-end 최적화는 우리가 아는 방식으로도 만들 수 있습니다.
예를 들어 위에서 소개한 이슈인 Simplification Comparison for (a | b) ? (a ^ b) : (a & b) etc. (Clang13 vs Clang trunk) 는 이슈 내용에도 나와있지만, 다음과 같은 최적화 되지 않는 사례에 대한 이슈를 제기합니다.
bool test3(bool a, bool b)
{
return (a & b) ? (a | b) : (a ^ b);
}
bool test4(bool a, bool b)
{
return (a & b) ? (a ^ b) : (a | b);
}
이슈에서는 이전 버전과의 차이를 말하고 있기 때문에 그 차이를 살펴보겠습니다.
// CLANG 13
define dso_local zeroext i1 @test3(bool, bool)(i1 zeroext %0, i1 zeroext %1) local_unnamed_addr #0 !dbg !24 {
call void @llvm.dbg.value(metadata i1 %0, metadata !26, metadata !DIExpression(DW_OP_LLVM_convert, 1, DW_ATE_unsigned, DW_OP_LLVM_convert, 8, DW_ATE_unsigned, DW_OP_stack_value)), !dbg !28
call void @llvm.dbg.value(metadata i1 %1, metadata !27, metadata !DIExpression(DW_OP_LLVM_convert, 1, DW_ATE_unsigned, DW_OP_LLVM_convert, 8, DW_ATE_unsigned, DW_OP_stack_value)), !dbg !28
%3 = or i1 %0, %1, !dbg !29
ret i1 %3, !dbg !30
}
// CLANG 13+
define dso_local noundef zeroext i1 @test3(bool, bool)(i1 noundef zeroext %0, i1 noundef zeroext %1) local_unnamed_addr #0 !dbg !34 {
tail call void @llvm.dbg.value(metadata i1 %0, metadata !36, metadata !DIExpression(DW_OP_LLVM_convert, 1, DW_ATE_unsigned, DW_OP_LLVM_convert, 8, DW_ATE_unsigned, DW_OP_stack_value)), !dbg !38
tail call void @llvm.dbg.value(metadata i1 %1, metadata !37, metadata !DIExpression(DW_OP_LLVM_convert, 1, DW_ATE_unsigned, DW_OP_LLVM_convert, 8, DW_ATE_unsigned, DW_OP_stack_value)), !dbg !38
%3 = zext i1 %0 to i32, !dbg !39
%4 = zext i1 %1 to i32, !dbg !40
%5 = and i32 %4, %3, !dbg !41
%6 = icmp eq i32 %5, 0, !dbg !42
%7 = or i32 %4, %3, !dbg !42
%8 = xor i32 %4, %3, !dbg !42
%9 = select i1 %6, i32 %8, i32 %7, !dbg !42
%10 = icmp ne i32 %9, 0, !dbg !42
ret i1 %10, !dbg !43
}https://godbolt.org/z/cTsd43jhh
이슈에 걸린 링크를 통해 두 컴파일러간의 차이를 확인할 수 있습니다.
위처럼 IR보려면 컴파일 옵션에 '-O2' 로 되어 있는데 '-S -emit-llvm' 을 추가해야 합니다.
이 이슈에서 삼항연산자의 최적화 결과물인 select 명령문은, 조건문이 참/거짓 항에 영향을 줄 수 있습니다.
예를 들어 A&B가 true이면 A=1, B=1 이고, false이면 A=1, B=1 이 아닌 조건이 소거되죠.
때문에 test3인 (a & b) ? (a | b) : (a ^ b); 의 진리표는, or 과 일치하고, or로 변경해도 됩니다.
이것을 어떻게 확인할 수 있냐? 바로 ALIVE2 입니다.
bool src(bool a, bool b)
{
return (a&b)?(a|b):(a^b);
}
bool tgt(bool a, bool b)
{
return a|b;
}
위처럼 최적화 하고자하는 대상과 최적화 될 결과값을 각기 src/tgt 란 이름의 C 함수로 만듭니다.
그리고 이를 컴파일하여 LLVM IR을 생성합니다.
clang-17 blog.cpp -S -emit-llvm -O2
cat blog.ll
; Function Attrs: mustprogress nofree norecurse nosync nounwind willreturn memory(none) uwtable
define dso_local noundef zeroext i1 @_Z3srcbb(i1 noundef zeroext %0, i1 noundef zeroext %1) local_unnamed_addr #0 {
%3 = zext i1 %0 to i32
%4 = zext i1 %1 to i32
%5 = and i32 %4, %3
%6 = icmp eq i32 %5, 0
%7 = or i32 %4, %3
%8 = xor i32 %4, %3
%9 = select i1 %6, i32 %8, i32 %7
%10 = icmp ne i32 %9, 0
ret i1 %10
}
; Function Attrs: mustprogress nofree norecurse nosync nounwind willreturn memory(none) uwtable
define dso_local noundef zeroext i1 @_Z3tgtbb(i1 noundef zeroext %0, i1 noundef zeroext %1) local_unnamed_addr #0 {
%3 = or i1 %0, %1
ret i1 %3
}
위처럼 생성된 IR을 ALIVE2에 접속해서 입력합니다.
https://alive2.llvm.org/ce/z/bKLUtw
Compiler Explorer - LLVM IR (alive-tv)
; Function Attrs: mustprogress nofree norecurse nosync nounwind willreturn memory(none) uwtable define dso_local noundef zeroext i1 @_Z3srcbb(i1 noundef zeroext %0, i1 noundef zeroext %1) local_unnamed_addr #0 { %3 = zext i1 %0 to i32 %4 = zext i1 %1 to i3
alive2.llvm.org
결과는 다음과 같습니다.
여기까지 진행됐다면, 최적화 대상을 찾고 본인이 만든 최적화 공식에 대한 증명이 된 것이므로 검증을 받을 최소한의 준비가 끝난 것 입니다. 만약 ALIVE2 가 없었다면, 본인이 만든 최적화 공식을 입증하기 위해 꽤 노력이 필요했을 겁니다 !!!
3. 코드 작성 tip
본인이 해결할 수 있는 최적화 방식에 대한 입증이 끝난 뒤라도 어떻게 기여할지는 막막한 일 입니다.
이럴때 가장 좋은 방법은 test 를 뒤져서 가장 유사한 케이스를 찾아보는 방법입니다.
위에서 살펴본 최적화는 select instruction에서 이뤄지게 되므로 select 관련 test를 찾아봅니다.
특히 위와 같은 Instruction 을 특정 Instruction으로 조합하거나 최소화 시키는 방식을 peephole 최적화라 부르고 주로 InstCombine 이나 InstructionSimplify 과정에서 진행하게 되므로 이에 한정해서 검색하면 됩니다.
https://github.com/ParkHanbum/llvm-project/commit/222bf3ffbc8419570fc2266a2e7d1c5f58cedaa7
Reapply [InstCombine] Simplify select operand based on equality condi… · ParkHanbum/llvm-project@222bf3f
…tion Reapply after fixing SimplifyWithOpReplaced() to never return the original value, which would lead to an infinite loop in this transform. ----- For selects of the type X == Y ? A : B, chec...
github.com
위처럼 select instruction의 condition에 기초한 최적화 방식을 여럿 찾을 수 있고, 교차 참조해서 코드를 작성하시면 됩니다.
4. PR 보내기 전 알아야 할 것.
코드를 작성하셨으면 PR을 보내기 전에 반드시 다음의 순서를 지키셔야 합니다.
A. test 를 먼저 작성하여 커밋.
B. 코드를 작성한 뒤 컴파일하고 생성된 바이너리(clang) 을 통해 test를 업데이트.
먼저 A에 대해 알아보겠습니다.
이 코드는 select instruction 과 관련된 최적화 이므로 llvm/test/Transforms/InstCombine/select.ll 에 테스트를 작성합니다.
테스트는 위에서 작성한 src/tgt 중에 src 로 작성된 IR을 사용하시면 됩니다.
여기서부터는 제가 작성했던 테스트를 예시로 들겠습니다.
; Select icmp and/or/xor
; https://alive2.llvm.org/ce/z/QXQDwF
; X&Y==C?X|Y:X^Y, X&Y==C?X^Y:X|Y
define i32 @src_and_eq_0_or_xor(i32 %x, i32 %y) {
%and = and i32 %y, %x
%cmp = icmp eq i32 %and, 0
%or = or i32 %y, %x
%xor = xor i32 %y, %x
%cond = select i1 %cmp, i32 %or, i32 %xor
ret i32 %cond
}
위처럼 자신의 테스트가 무엇을 위한 것인지를 이름을 짓습니다.
src 접두어는 alive2에서 증명했던걸 그대로 가져와서 남았고 필수가 아닙니다.
여기서 update_test_checks.py 를 돌리면 되는데 예제는 다음과 같습니다.
./llvm/utils/update_test_checks.py --opt-bin ../i71792/bin/opt llvm/test/Transforms/InstCombine/select.ll
update_test_checks.py는 llvm-project에 포함되어 있으므로 llvm-project root 에서 실행하면 위와 같은 명령어가 나옵니다.
../i71792/bin/opt 은 되도록 최신 버전의 llvm 바이너리 중 하나인 opt 의 경로를, llvm/test/Transforms/InstCombine/select.ll 은 방금 작성한 테스트 파일의 경로를 넣어주면 됩니다.
위의 명령을 실행하면 우리가 작성한 테스트 IR에는 주석이 붙습니다.
; Select icmp and/or/xor
; https://alive2.llvm.org/ce/z/QXQDwF
; X&Y==C?X|Y:X^Y, X&Y==C?X^Y:X|Y
define i32 @src_and_eq_0_or_xor(i32 %x, i32 %y) {
; CHECK-LABEL: @src_and_eq_0_or_xor(
; CHECK-NEXT: entry:
; CHECK-NEXT: [[AND:%.*]] = and i32 [[Y:%.*]], [[X:%.*]]
; CHECK-NEXT: [[CMP:%.*]] = icmp eq i32 [[AND]], 0
; CHECK-NEXT: [[OR:%.*]] = or i32 [[Y]], [[X]]
; CHECK-NEXT: [[XOR:%.*]] = xor i32 [[Y]], [[X]]
; CHECK-NEXT: [[COND:%.*]] = select i1 [[CMP]], i32 [[OR]], i32 [[XOR]]
; CHECK-NEXT: ret i32 [[COND]]
;
entry:
%and = and i32 %y, %x
%cmp = icmp eq i32 %and, 0
%or = or i32 %y, %x
%xor = xor i32 %y, %x
%cond = select i1 %cmp, i32 %or, i32 %xor
ret i32 %cond
}
이런 구조가 됩니다.
주석으로 붙은 IR 이 인자로 넣어준 opt가 생성한 최적화 된 IR 입니다. 만약 해당 IR이 우리가 작성한 테스트와 일치하지 않는다면, 우리가 작성한 IR에는 최적화가 가능한 코드 구문이 존재한다는 뜻 입니다. 그러므로 이를 반영해서 IR을 수정하던가 아니면 최적화가 되지 않도록 만드는 기법을 사용해야 합니다.
보통 InstCombine은 모든 최적화가 명령을 합치거나 치환하는 과정이므로 다른 곳에서 명령을 참조하면 최적화가 진행되지 않습니다. 이를 응용해 use()같은 함수를 하나 만들어 최적화가 되버리는 IR을 인자로 넣어주면 최적화가 되지 않습니다.
%m = mul i32 %x, %y
call void @use_i32(i32 %m)
이런 식 입니다.
자, 이제 test를 commit 합니다.
https://github.com/llvm/llvm-project/pull/73362/commits/edeaf1cf4fa58f88d4061634bd9514dab07d4484
[InstCombine] Simplify select if it combinated and/or/xor by ParkHanbum · Pull Request #73362 · llvm/llvm-project
and/or/xor operations can each be changed to sum of logical operations including operators other than themselves. x&y -> (x|y) ^ (x^y) x|y -> (x&y) | (x^y) x^y -> (x|y) ^ (x&y) if left of condition...
github.com
그럼 위 커밋처럼 온전히 현재 LLVM버전에서 최적화가 되지 않는 IR에 대한 케이스만 담겨있게 됩니다.
이제 A는 끝났습니다.
B. 코드를 작성한 뒤 컴파일하고 생성된 바이너리(clang) 을 통해 test를 업데이트.
이제는 코드를 작성후 컴파일을 합니다. 그리고 A 때와 마찬가지로 update_test_checks.py 를 돌립니다.
그러면 이번에는 최적화가 된 IR로 주석이 교체되게 될 겁니다.
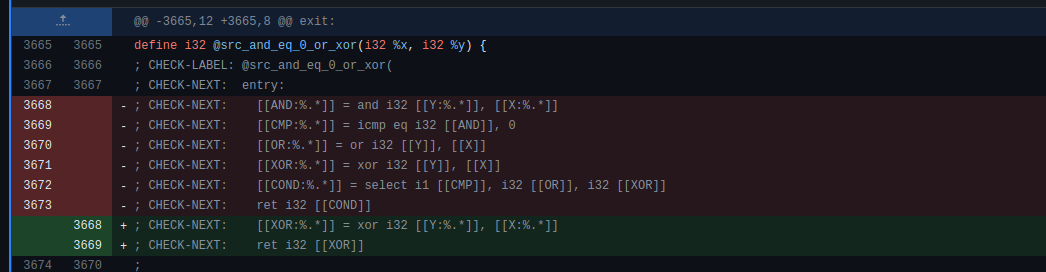
위처럼 git 을 통해 보면 확실히 변경 사항을 확인할 수 있습니다.
첫 번째 커밋으로 *아직* 최적화가 되지 않는 IR과 실제 opt 를 통해 최적화가 되지 않는 IR을 주석으로 남긴 테스트를 추가했다면,
두 번째 커밋에는 최적화 되지 않는 IR 이 내가 작성한 코드를 컴파일 한 opt를 통해 최적화 된 결과로 기존 최적화되지 않은 주석 IR 을 최적화 된 IR로 교체한 내용과 그 최적화를 가능케 한 코드가 담기게 됩니다.
아래 링크처럼요.
https://github.com/llvm/llvm-project/pull/73362/commits
[InstCombine] Simplify select if it combinated and/or/xor by ParkHanbum · Pull Request #73362 · llvm/llvm-project
and/or/xor operations can each be changed to sum of logical operations including operators other than themselves. x&y -> (x|y) ^ (x^y) x|y -> (x&y) | (x^y) x^y -> (x|y) ^ (x&y) if left of condition...
github.com
여기까지 왔다면 거의 PR 준비가 끝난 겁니다.
마지막으로 ninja 혹은 make 에 check-all 을 붙여 다른 테스트들도 통과하는지 확인하고 PR을 보내면 됩니다.
해당 과정은 LLVM에 패치보니기 튜토리얼 링크를 참조해주세요.
'LLVM-STUDY' 카테고리의 다른 글
| computeKnownBitsFromCond (0) | 2024.05.01 |
|---|---|
| LLVM 원라인 패치 목록 (0) | 2024.03.17 |
| LLVM debug tips (0) | 2024.01.14 |
| LLVM 내부에서 활용되는 논리식 모음 (0) | 2023.12.15 |
| [TODO] DomConditionCache (0) | 2023.12.11 |