
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 난독화
- android inject
- on-stack replacement
- v8 optimizing
- initial-exec
- Obfuscator
- tracerpid
- linux thread
- Linux packer
- custom packer
- TLS
- so inject
- 안티디버깅
- LLVM
- linux debugging
- pinpoint
- LLVM Obfuscator
- Injection
- Android
- on stack replacement
- Linux custom packer
- uftrace
- v8 tracing
- LLVM 난독화
- tracing
- apm
- anti debugging
- pthread
- OSR
- thread local storage
- Today
- Total
Why should I know this?
Vector 에서의 비교문 (icmp, fcmp) 의 특징 feat.ChatGPT 본문
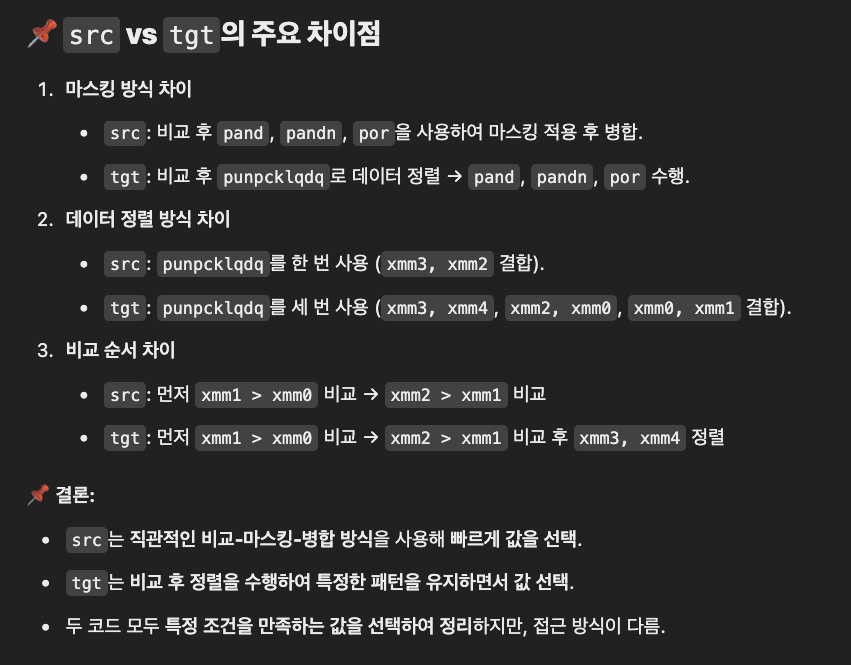
위 IR @src 와 @tgt 는 동일한 기능을 하는 IR입니다.

그러나 "벡터" 연산의 특징에 대해 이해를 하지 못한다면 위처럼 생각해서 틀렸다고 생각하기 쉽습니다.
이와 관련된 검증을 ChatGPT와 해본 글을 올렸으니 관심있으면 보세요
업데이트 된 ChatGPT-o4와 토론 - 주제는 LLVM 최적화가 올바른지 여부 | 박한범
DeepSeek가 등장한 이후 ChatGPT는 o4모델로 업데이트 되었습니다. 다음은 ChatGPT와 함께 VectorCombine 최적화 샘플을 검증해본 대화의 요약입니다.
kr.linkedin.com
 |
 |
컴파일된 두 IR 이 생성한 어셈블리를 통해 이 IR 이 동일한 결과를 만드는지 벡터연산의 특징을 이해해봅시다.
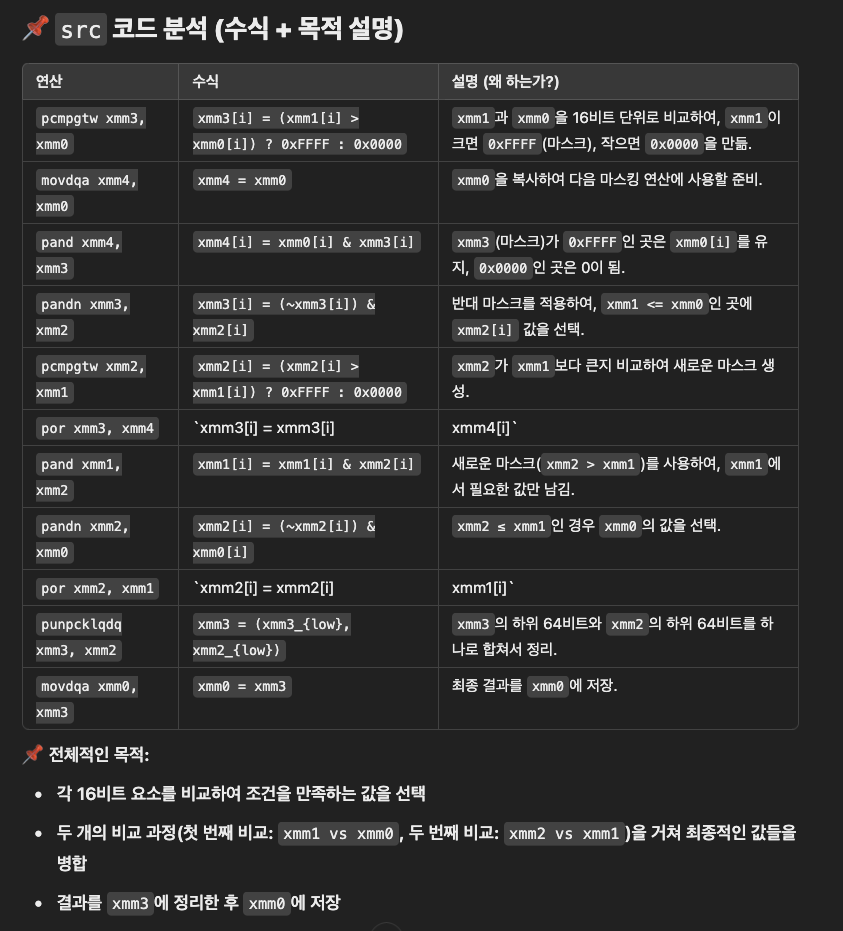
우리가 일반적인 산술연산에서 cmp 이후 select 에서 기대하는 바는,
x < y ? x : z
입니다.
그러나 벡터 연산에서는 x 가 각각 i16 타입의 변수 네개의 집합체라고 생각해야 합니다.
즉, 네 번의 비교와 선택을 for 문 없이 연속한다고 보면 됩니다.
temp[i] = x[i] < y[i] ? x[i] : z[i]
단지 위 산을 xmm 레지스터를 활용해서
pcmpgtw xmm3, xmm0
연산을 수행하는 차이가 있습니다.
여기서 이 명령어 뜻을 보고 다음으로 넘어갑시다.
- pcmpgtw → Packed Compare Greater Than Word
- P → Packed (벡터 연산)
- CMP → Compare (비교 연산)
- GT → Greater Than (초과 비교)
- W → Word (16비트 단위)
- 즉, 각 16비트(word) 요소별로 비교하여 크면 0xFFFF, 작거나 같으면 0x0000을 설정하는 명령어.
여기까지는 정리가 됐죠?
그러면 변수 x, y, z 가 i16 타입 변수 4개의 집합체니까 compare 도 각자 했기 때문에,
select 문도 마찬가지로 변수 4개 각자 처리되냐? 라고 묻는다면 감이 좋으신 겁니다.
단지, 이 연산을 보다 빠르게 처리할 방법이 있습니다.
우리는 앞서 벡터 안의 i16타입 변수 네 개를 각자 비교연산 후 결과를 temp 에 저장했죠?
그럼 각 변수의 크고 작음이 0000 이나 FFFF 로 temp 에 저장됩니다.
예를 들어, x[0] 이 1이고 y [0]이 2이면, x < y 는 참이죠. temp 에는 0xFFFF 를 저장합니다.
반면, x[0] 이 2이고 y[0]이 1이면, x < y 는 거짓이죠. temp 에는 0x0000 을 저장합니다.
그러면 temp 와 x 와 AND 연산을 하면
res[i] = x[i] < y[i] ? x[i] : y[i]
res에는 x < y 인 경우에 해당하는 i 순서에 x의 값이 담기게 됩니다.
어셈블리어는 여기입니다.
pand xmm4, xmm3
그럼 이제 x < y 가 아닌 경우에 해당하는 i 순서의 값도 담아야겠죠?
그는 ~temp[i] 와 And 연산을 해주면 됩니다.
어셈블리어는 여기입니다.
pandn xmm3, xmm2
이렇게 연산한 결과를 모으면 최종 res가 되는 것이고 어셈블리어는 여기입니다.
por xmm3, xmm4
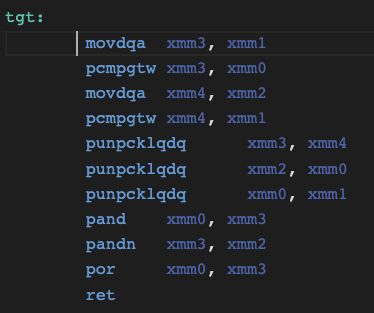
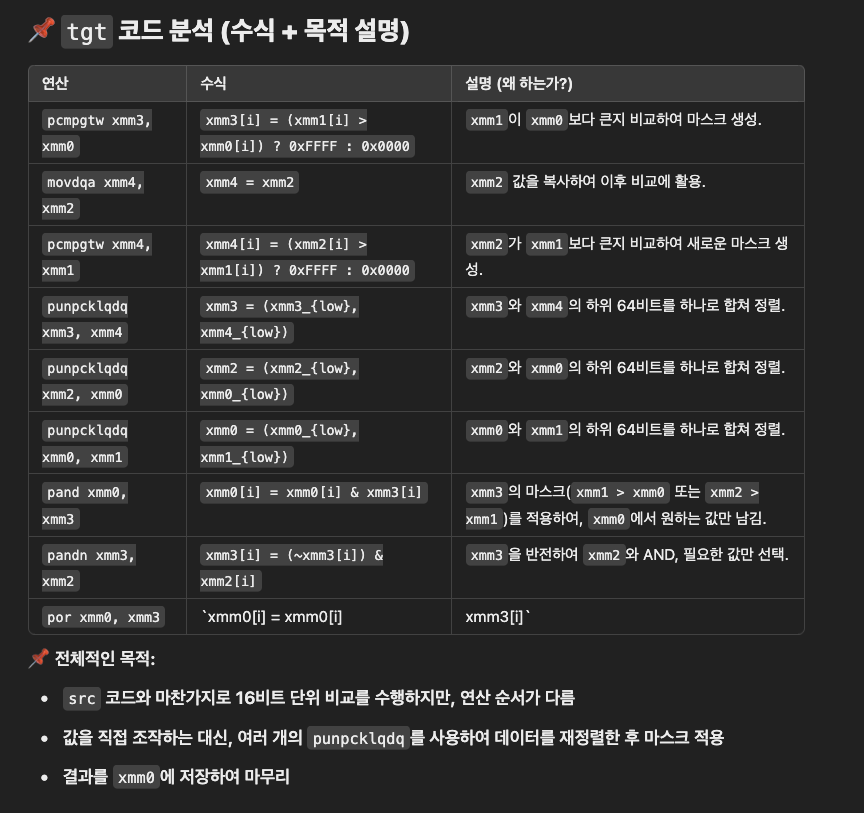
Src의 x, y 에 대한 cmp와 select 는 여기까지이고 다음으로 y, z 에 대한 cmp와 select를 동일하게 수행합니다.
이후에 x,y 에 대한 결과와 y,z에 대한 결과를 shufflevector로 섞어주는 것으로 마무리가 됩니다.
어셈은 여깁니다.
punpcklqdq xmm3, xmm2
여기서 이 명령의 뜻을 알고 넘어갑시다.
- punpcklqdq → Packed Unpack Low Quadword
- P → Packed (벡터 연산)
- UNPCK → Unpack (데이터를 섞는 작업)
- L → Low (하위 64비트 사용)
- QDQ → Quadword to Quadword (64비트 단위로 연산)
- 즉, 하위 64비트(quadword)끼리 언패킹하여 하나의 128비트 레지스터를 구성하는 명령어.
xmm3 의 하위 64비트와 xmm2의 하위 64비트를 묶는 명령입니다.
여기서는 두 결과를 하나로 묶기 위해 사용됐습니다.
여기서 우리가 벡터연산의 특징이라고 확인한 것은,
벡터는 동일타입 변수의 "묶음"이고 비교할 때 각 변수를 독립적으로 비교한다는 것 입니다.
1. x < y , y < z 비교 값을 합쳐 <8 x i8> 로 묶고
2. 조건이 true/false 에 따라 선택될 값 조합을 하나의 벡터 <8 x i16>으로 묶어
2.1 true 일 때는 x y
2.2 false 일 때는 y z
3. select를 하는 것이
동일한 결과를 만들어 낸다는 결론을 낼 수 있습니다.
다음은 위의 설명을 ChatGPT가 요약한 자료 입니다.
- 끗 -
'LLVM-STUDY' 카테고리의 다른 글
| Dominate, DominateTree (0) | 2025.04.15 |
|---|---|
| Revert 된 커밋 다시 올릴 때 참고 (0) | 2024.09.07 |
| computeKnownBitsFromContext (0) | 2024.05.01 |
| computeKnownBitsFromCmp (0) | 2024.05.01 |
| computeKnownBitsFromICmpCond (0) | 2024.05.01 |
