

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Obfuscator
- TLS
- on-stack replacement
- custom packer
- Android
- 안티디버깅
- linux thread
- LLVM
- on stack replacement
- anti debugging
- pthread
- Linux custom packer
- OSR
- linux debugging
- Injection
- v8 optimizing
- apm
- LLVM Obfuscator
- tracing
- tracerpid
- thread local storage
- android inject
- v8 tracing
- pinpoint
- initial-exec
- uftrace
- Linux packer
- 난독화
- so inject
- LLVM 난독화
- Today
- Total
Why should I know this?
Tracing 에 대한 고찰 (feat, pinpoint) 본문
오픈소스 uftrace(https://github.com/namhyung/uftrace)의 개발에 참여하면서, Tracing 도구를 개발하고 동시에 이용하는 입장으로서 Tracing에 대한 고찰을 정리해보고자 한다.

지난 주에 Naver에서 주최한 Pinpoint 세미나에 참석했었다.

Pinpoint는 Naver에서 개발하여 공개한 오픈소스이며, APM (Application Performance Management) 도구이다. 위 그림처럼 Pinpoint는 수려한 UI를 갖추고 있다. 고품질의 UI에 걸맞게 Pinpoint는 github에서도 인기가 좋다. (https://github.com/naver/pinpoint) 8,900의 스타로 9천개 스타에 진입하고 있다. 국내 IT 대기업들은 자체적으로 개발한 도구, 라이브러리 등을 오픈소스로 공개하는 활동을 하고 있지만, 그 대부분이 적은 수의 스타를 받을 수 밖에 없는 사용층이 옅고 사내용으로 개발한 프로젝트인 것과 비교할 때 Pinpoint는 매우 성공적으로 오픈소스화 된 프로젝트라고 할 수 있다.
내가 Pinpoint에 주목한 이유는, 애초에 Tracing 도구의 유용성을 체험하면서 uftrace의 개발에 참여하게 되었지만, Android, GCC, v8과 같은 거대 오픈소스를 분석하면서 Tracing이 가진 명확한 한계점을 느끼게 되었으며, 그 한계점을 극복하지 않고는 극소수의 사람들에게 좁은 의미의 유용성을 제공하는데 그치게 된다는 결론을 내렸다. 말이 기니 세 줄 요약하자면 다음과 같다.
- Tracing 도구의 유용성을 느껴 개발에 참여
- Tracing 도구를 통해 다양한 오픈소스를 Tracing 해보니 Tracing의 유용성이 명확한 한계점을 드러냄
- 개선 방안에 대한 고민을 하게 됨
한계점을 해결하기 위한 요소는 다양할 수 있겠지만, 나는 '분류'를 그 해결책으로 생각했으며, Naver Pinpoint는 이와 같은 나의 결론을 제대로 증명해주는 프로젝트라고 감히 생각한다.
먼저 Tracing이 무엇인지에 대해 설명하자면,
wikipedia에서 Tracing(https://en.wikipedia.org/wiki/Tracing_(software)) 은 다음처럼 언급되어 있다.
In software engineering, tracing involves a specialized use of logging to record information about a program's execution. This information is typically used by programmers for debugging purposes, and additionally, depending on the type and detail of information contained in a trace log, by experienced system administrators or technical-support personnel and by software monitoring tools to diagnose common[citation needed] problems with software. Tracing is a cross-cutting concern.
누가 - 프로그래머, 시스템 운영자, 테크니컬 서포터
무엇을 - 프로그램의 실행 기록에 대한 정보 (log 등)
왜 - 문제의 원인 추적
어떻게 - 소프트웨어 모니터링 도구 등을 통해
일반적으로 개발자들이 DEBUG/RELEASE를 구분해서 빌드하며, DEBUG로 빌드 시에 각종 DEBUG 목적의 메시지 출력문을 추가하는데 이와 같은 내용들을 분석하는 일을 Tracing이라고 부른다.
Tracing, “프로그램의 실행 동안의 변화를 다각도로 기록하고 이를 검토하는 일
물론 개발자들이 수작업으로 메시지를 추가할 수도 있는데, 컴파일러가 이를 지원하기도 한다. gcc나 llvm은 'pg', 'finstrument-functions'와 같은 옵션을 통해 함수의 시작과 끝부분에 임의의 함수를 호출하는 구문을 추가한다. 이를 통해서 gcov, gprof와 같은 3rd-party 성격의 툴들이 나오게 된다. Uftrace도 이와 같은 메커니즘을 활용하고 있다. 다음 그림을 통해 자세히 살펴보자.


차이점이 보이시는지 모르겠다. 거의 차이가 없으니까 말이다.

-pg옵션을 사용하면 함수 시작 지점에 mcount라는 함수를 호출하는 구문이 추가되며, 이는 weak symbol로 선언된다. 따라서 별다른 절차 없이도 사용자가 선언한 mcount 함수로의 linking을 유도할 수 있다. 쉽게 말해 별다른 절차없이 각 함수의 호출을 hooking 할 수 있다는 뜻이다. 또한 이처럼 본래 목적의 코드가 아닌 특별한 목적의 Instruction을 주입하는 기법을 Instrument라고 한다.
Uftrace는 이 외에 다른 요소들을 공격적으로 활용하여 다양한 각도로 프로그램의 실행을 기록한다.


이렇게 기록된 실행 흐름을 통해 다음과 같은 간단한 프로그램 실행 기록을 얻을 수 있다.

만들어논 자료가 당연하게도 내가 참여하고 있는 Uftrace에 대한 자료이지만, 사실 이와 같은 구조를 가장 먼저 채용하고 있는 오픈소스는 다름아닌 Linux Kernel이다. Linux Kernel에는 Perf라는 컴포넌트가 있으며 이 Perf가 정확히 위에서 Uftrace에 대해 설명한 구조와 똑같은 방식으로 Linux Kernel에 대한 실행 흐름의 기록을 지원한다.
Netflix의 brendan gregg은 시스템 아키텍처로 Perf 를 통해 성능 최적화 및 장애 해결을 업무로 하고 있다. 그의 발표에서 perf를 통해 linux kernel부터 데이타베이스로 쓰고 있던 cassandra에 걸친 광범위한 트레이싱을 하고 마침내 Paging Size의 변화로 인한 Page fault의 증가라는 장애 원인을 찾는 과정을 통해 Tracing이 현업에서 어떻게 사용될 수 있는지 간접적으로나마 느껴볼 수 있다.
Tracing은 특정 목적을 가진 프로그래머 혹은 Brendan Gregg과 같은 전문적인 시스템 전문가가 시스템의 전반에 걸친 프로그램의 실행기록을 검토하고 장애 요소를 찾아내는데 유용한 도구라는 것은 이미 공인된 사실이다. 하지만 이와 같은 유일하게 공인된 Tracing의 유용성도 Brendan Gregg의 발표 내용을 보면 실질적으로는 리눅스 커널에 대한 깊은 이해와 분석력이 뒷바침되지 않고는 결코 성공할 수 없는 경우였다.
이것이 결국은 Tracing이라는 용어와 그 목적의 한계인 것이다.
"프로그램 실행 기록을 다각도로 기록"하는 도구는 Perf, Uftrace와 같은 도구의 도움을 받을 수 있지만, 이것은 부차적인 것이고 실제 그 기록의 검토 단계로 넘어가면 결국 개인의 역량에 모든 것을 걸게 된다. 도구의 유용성은 검토하는 사람의 스킬과 역량에 비례하게 되거나 또는 부가적인, 없어도 있어도 그만인 존재가 되어버린다.
예를 들어, Node.js에서는 성능이점을 위해 Native에서 연산을 하는 함수들을 Javascript에서 사용할 수 있도록 지원한다.
하지만 Native에서 연산을 한다고 항상 Javascript보다 빠르지 않다.
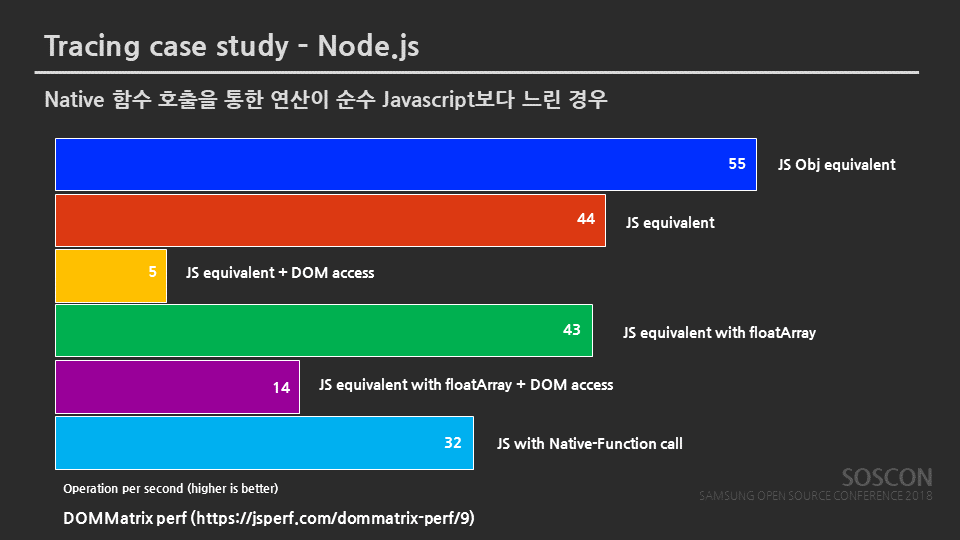
그 이유는 다음과 같다.

Uftrace로 Node.js를 Tracing해보면 위와 같은 부분이 무수히 파편적으로 나오며, 그 의미는 그림에서 설명하듯, Javascript와 Native에서 데이터를 주고 받기 위해 Type을 검사하는 코드이다. 이 코드가 Javascript-Native간의 데이터 이동에 병목으로 작용하여 연산 자체는 Native가 빠름에도 불구하고 Native 함수의 호출이 Javascript에서 연산하는 것보다 느려지게 되는 문제를 발생하는 것이다.
위의 예는 Chromium Project Onwer신 방진호님이 분석한 내용이다. 거듭 강조하고자 하는 것은 분석하려는 프로젝트에 깊은 이해와 조예가 있어야 비로소 Tracing은 그 의미를 갖는 것이다.
나는 예전에 Gcc에서 특정 문제를 발견하고 이유를 Tracing 해보고자 하였었다. 하지만 415만에 걸친 방대란 기록 자체도 분석하기 버거울 정도의 양이었지만, 더 큰 문제는 Gcc와 같이 사소한 변화가 수 많은 가지로 분기되는 프로그램의 경우 분석해야 할 포인트 조차 찾을 수가 없었다는 것이다. 때문에 Gcc로부터 부가적인 데이터를 추가해야 했으며, 그것이 '-fdump-tree-all-details'라는 디버깅 로그이다. 해당 디버깅 로그가 없었다면 결코 문제의 원인을 찾고 그를 수정하지 못했을 것이다.
여기까지가 Tracing에 대한 설명과, 내가 왜 그에 한계점을 느끼게 됐는지에 대한 간소한 설명이다.
근데 여태 설명한 내용이 Pinpoint와는 어떤 연관성이 있는걸까?
"본래 목적의 코드가 아닌 특별한 목적의 Instruction을 주입하는 기법을 Instrument라고 한다."는 설명을 앞서 드렸다. 이와 같은 기법을 사용할 수 있도록 컴파일러들이 옵션을 제공한다는 설명도 앞서 드렸다. 근데 어디까지나 이는 컴파일 시에 제공되는 기능이다. 그렇다면 Java나 Javascript, 혹은 Python은 어떨까?
그렇다.
위의 기법이 제공될 수도 아닐 수도 있다.
Pinpoint는 Java 및 PHP 를 지원하며, 해당 대상에 대한 Instrument 기능을 갖추고 있다는 것이 기존의 APM들과 차별화되는 요소라고 할 수 있다. 나는 AOSP를 분석하는 과정에서 JVM와 유사한 Dalvik을 분석해봤고, 덕분에 JVM에서 CLASS가 로드되고 METHOD가 호출되는 과정에 대해 상세하게 알게 됐다. JVM의 특징 중에 하나는 CLASS를 로드하는 Classloader의 교체가 허용되고 쉽다는 점이다. 그러므로 클래스가 로드될 때에 Bytecode를 삽입하는 방법을 택하지 않았을까 하는 예상을 해본다. 어쨌든, Pinpoint의 이런 요소는 오히려 APM보다 Tracing에 가까운 것이라고 할 수 있다.
내가 놀란 것은 바로 이 점이다. 일반적인 APM은 CPU, I/O, RAM 등 OS에서 제공해주는(Java의 경우 JVM) Performance monitoring 포인트를 읽어들여 기록하고 이를 UI 등을 통해 시각화해 전달해주는 것이 고작이다. 그러므로 Application과 Database, Application과 I/O, Application과 Async 등 수 많은 포인트에 대해서 원하는 데이터가 제공되지 않으면 그를 직접 로깅하는 것 외에는 다른 방도가 없었다.
하지만 Pinpoint의 경우 Java Bytecode에 Instrument를 하는 고난의 길을 택했고, 그를 성공적으로 완수해냄을 통해 Java와 Database 간에, Java와 Network 간에 이벤트 또한 기록하는 것이 가능하게 된 것이다. 그리고 Pinpoint 세미나에서는 Apache OpenWhisk라는 오픈소스를 Tracing하는 것을 Plugin으로 개발한 내용도 함께 소개되어 재밌었다.
기존의 APM들이 OpenWhisk를 사용하는 백엔드 환경에서 서버간 Tracing을 지원하려면 어떻게 해야 될까? OpenWhisk에서 동작할 코드들에 수동으로 Tracing을 위한 로그를 기록하게 하고 그를 수집하는 서버를 구축해야 하겠지. 비교해서 생각해보면 Pinpoint가 얼마나 사용하기 좋은지 알 수 있다.
다시 말하자면, Pinpoint는 Java에서 사용되는 수많은 기록을 전문가들이 충분히 검토하여 그를 APM이라는 일종의 평가 기준에 녹여냄을 통해서 Tracing에 정량적 평가를 부여한 것이다. 그리고 이 평가 기준은 이미 대중적으로 상업적으로 어느정도는 성공적으로 인정받기도 했다.
나 또한 개인의 역량에 모든 것이 일임되는 Tracing이 범용적 의미를 갖게 하기 위해서는 "분류"가 반드시 필요하다고 결론냈다. "분류"란 분석 대상의 기록을 검토하고 해당 기록들이 어떤 동작인지 분류하여 정량적인 내용을 붙이는 것을 말한다. Node.js를 예를 들어보자.
var handler = function (req, res) {
// 여기에 Instrument하여 처리 시작을 기록
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end('Hello World\n');
// 여기에 Instrument하여 처리의 종료를 기록
};
var server = http.createServer();
server.setSecure(credentials);
server.addListener("request", handler);
server.listen(8000);위의 코드에 주석처럼, 각 함수의 시작과 종료에 Instrument하여 그를 기록하되, 그 함수가 어떤 역할과 동작을 하는지 HTTP REQUEST로 선분류를 해놓으면, 이는 Network라는 대분류로, HTTP REQUEST라는 소분류로 APM에서 보여줄 수 있는 것이다. 이처럼 Database, I/O등도 분류하기 시작하면 Tracing을 기반으로 한 APM을 구축할 수 있다. 또한 이와 같은 분류가 지속적으로 유지보수 되게 되면, 각각의 개발자가 자신들이 활용하는 환경을 위한 분류를 공유하고 점진적으로 세밀하게 해진 분류는, 마침내 내가 Tracing을 통해 이루고자 했던 목표인 문외한도 Tracing을 통해 코드 흐름을 파악할 수 있게하는 수준에 이를 수 있을 것이다.
나와 같은 목적성을 Pinpoint가 가지고 있을 것이라고는 결코 생각하지 않지만,
결국 그런 그림을 구성하는 것을 경쟁우위로 삼고 있는 Pinpoint이기에 응원하게 된다.
'Knowledge > Tracing' 카테고리의 다른 글
| gcc를 분석하는데 도움이 되는 컴파일 옵션 (0) | 2018.06.25 |
|---|---|
| Tracing을 도와주는 컴파일 옵션들. (0) | 2018.06.10 |