
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- v8 optimizing
- TLS
- LLVM 난독화
- 난독화
- custom packer
- initial-exec
- linux thread
- android inject
- anti debugging
- OSR
- Android
- pthread
- LLVM
- 안티디버깅
- so inject
- pinpoint
- Linux packer
- on-stack replacement
- linux debugging
- tracing
- uftrace
- thread local storage
- Injection
- on stack replacement
- Obfuscator
- v8 tracing
- LLVM Obfuscator
- tracerpid
- apm
- Linux custom packer
- Today
- Total
Why should I know this?
역공학(=Reverse Engineering)을 위한 컴퓨터 기본 원리 본문
역공학이란 ?
역공학이란 대상에 대해 알려진 정보를 기반하여 설계 구조와 원리를 역으로 추적하는 공학 기법을 의미합니다. 프로그래밍 언어로 작성된 소스코드가 컴파일 되어 프로그램이 됩니다. 여기서 우리가 다루고자 하는 내용은 우리가 익히 알고 있는 내용(=프로그래밍 언어를 컴파일 하는 방법, 원리, 구조에 대한 정보)에 기반하여, 컴파일 된 프로그램의 구조와 원리를 역으로 추적해내는 방법입니다.
역공학은 해커들에게 기본 중에 기본인 소양입니다. 해킹을 배우고자 하는 사람들에게 프로그래밍 언어를 먼저 배우라고 권하는 이유가 여기 있습니다. 해킹이란, 프로그램(=커널 등을 포함한)의 구조와 원리를 역으로 추적하여 그 과정과 기술적 설계에 문제의 여지가 없는지를 찾아내는 학술이기 때문입니다.
하지만 꼭 프로그래밍을 할 줄 알아야 하나? 그렇지는 않습니다. 프로그래밍이란 결국 컴파일러에 의해 기계어로 번역되는 사람이 사용하기 편한 표현물에 불과합니다. 중요한 것은 프로그래머들이 프로그램을 만드는 근본적인 구조와 원리이고 이것은 프로그래밍 언어에 종속되지 않는 컴퓨터의 구조에 대한 이해에서 비롯된 이론적 분야이기 때문입니다.
이 페이지에서는 LLVM IR을 통해 C, C++ 과 같은 프로그래밍 언어를 관통하는 근본적인 컴퓨터 원리를 공부하는 것을 목적으로 합니다.

현대 컴파일러는 Front-end, Optimizer, Back-end의 3단 구조로 설계됩니다.
Front-end는 프로그래밍 언어의 표현을 해석하는 역할을 합니다. 프로그래밍 언어에서 사용하는 키워드, 문법 등을 해석해서 바르지 않는 부분이 있으면 Warning 혹은 Error를 통해 프로그래머에게 알려주는 기능이 대표적입니다.
Optimizer는 프로그래머가 짠 코드를 최적화 합니다. 예를 들어, 변수를 선언하고 사용하지 않으면 제거하고, 추정가능한 경우 크기를 조절하는 등 다양한 방법으로 최적화를 합니다.
Back-end는 대상 환경에 맞는 프로그램을 만드는 작업을 합니다.
C컴파일러로 가장 유명한 Gnu C Compiler(=GCC)의 경우 C를 위한 컴파일러로 시작됐습니다. C를 위한 Front-end와 Optimizer를 포함한 Back-end의 구조를 갖고 있었으나, 이후 다양한 프로그래밍 언어들이 생기면서 gcc가 가진 Back-end를 사용하기 시작했고, 컴파일러의 구조는 보다 복잡해지게 됩니다.
gcc가 현대에 이러 3단 구조를 갖게 되면서, gcc의 back-end를 사용하는 새로운 프로그래밍 언어를 만들기 용이해졌습니다. 원하는 대상과 구조에 따라 Front-end만 만들면 gcc를 통해 컴파일 할 수 있습니다.
LLVM 소개
LLVM은 gcc의 구조를 충실히 따르고 있습니다. 동시에, gcc가 3단 구조의 모듈로 나뉜 것에 추가로 PASS라는 개념을 만듭니다. 이에 대한 내용은 글의 범위를 넘어서기에 생략하고, gcc가 3단 모듈 구조로 나뉘었어도 여전히 비전문가들이 접근하기 어려웠는데 각 모듈을 보다 잘게 나눠 비전문가들도 접근하기 쉬운 구조로 이뤄졌다고 생각하시면 됩니다. 이런 장점으로 인해 수 많은 프로젝트들이 LLVM을 기반으로 이뤄지고 있습니다. LLVM 홈페이지에 가면 관련 논문 및 프로젝트들을 모아놓은 곳이 있으니 가보시면 재미있을 겁니다.
LLVM IR 소개
이번 글에서는 LLVM의 IR이 주인공입니다. LLVM의 IR을 통해 우리는 프로그래밍 언어의 근본적인 영역을 훔쳐 볼 것입니다. LLVM의 IR이란 Intermediate Representation의 약자로, 번역하면 "중간 표현체" 정도가 됩니다. 이 IR은 LLVM의 프로그래밍 언어로 짜여진 소스가 Front-end를 통과하면 나오는 결과물입니다. LLVM IR은 기계어로 번역되기 전에 사람이 읽기 편한 마지막 표현이고 또한 특정 CPU에 비종속적인 형태이기 때문에 특정 어셈블리어를 익히기 전에 쉽게 다가갈 수 있는 장점이 있습니다.
LLVM IR을 통해 우리가 배우고자 하는 것은 보다 근원적인 내용이고, 이런 내용은 프로그래밍 언어에서 사람이 쓰기 편하고자 만든 표현이 실질적으로 어떤 구조를 갖는지 탐색하는 것이 하나의 방법이 될 수 있습니다.
C 언어 뒤집어 생각하기
프로그래밍 언어가 어렵게 느껴지는 이유는 다양하겠지만, 언어 자체가 추상적인 것이 큰 몫을 합니다. 예를 들어, 사과-APPLE은 현실에 존재하고 자주 접하는 사물의 표현이기 때문에 쉽게 이해하고 외울 수 있습니다. 그에 비해, 함수-function이나 포인터-pointer는 볼 수도 만질 수도 없는 추상적인 어떤 기능에 대한 명칭이라 확실히 인지하기 전에는 어렵게 느껴질 수 밖에 없는 것입니다.
프로그래밍 언어의 근원을 공부하고자 하는 사람이라면 반드시 주지해야 할 점은, 프로그래밍이란 결국 머신(=CPU혹은 컴퓨터)과 소통하기 위한 도구라는 점 입니다. 그러므로 그 범위는 머신에 국한됩니다.
그렇다면 머신이 할 수 있는 일이란게 뭘까요?
머신이 할 수 있는 일은, 0과 1로 이루어진 바이너리(binary : 0과 1로 이루어진 파일 혹은 덩어리)를 읽어와 그것을 명령어(Operator)와 피연산자(Operand)로 인식한 뒤에 더하거나 빼거나 나누거나 곱하는 오로지 숫자 연산을 수행하고 그 결과를 저장하거나 반환하는 것이 고작입니다. 프로그래밍 언어도 아무리 복잡하게 보이더라도 결국 이런 동작을 수행할 뿐이라는 점을 주지하시길 바랍니다.
"프로그래밍 언어(+컴파일러)는 결국 임의의 값 x를 원하는 연산 과정 Program(x)을 거쳐 결과 값을 만드는 프로그램을 만드는 도구이다."
변수
변수란, 수학에서 사용되는 변수 x와 마찬가지로 "값을 저장하는 공간"입니다. 컴퓨터 입장에서는 "프로그램이 값을 저장하는 공간"이 되겠죠. 위에서 언급한 프로그래밍 언어의 정의에 따라, 변수는 프로그래머가 의도한 연산결과를 만드는 시작점이자 요소가 됩니다. 그런 측면에서, 역공학에서는 핵심적인 역할을 하는 것과 아닌 것을 구분하고 그 값의 변화를 통해 함수의 연산 과정을 추정하는 단서와 같은 역할을 합니다.
C언어에서는 char, short, int 와 같은 다양한 형태를 가진 변수를 지원합니다. 변수 형이란, 사용할 메모리 사이즈에 따라 변수의 형태를 명시적으로 선언하는 것을 일컫습니다. 프로그래머들에게 원하는 만큼의 메모리 공간을 할당할 수 있게 제공하는 기본적인 형태로, 1btye~8byte까지 컴파일러 별로 다양한 크기와 형태를 제공합니다. 해당 내용은 C언어 관련해서 더 살펴보기로 하고, 이번에는 변수의 저장공간과 그 공간에 접근하는 방식을 살펴보고자 합니다.
컴퓨터에서 변수는 저장되는 장소에 따라 세 곳으로 나눌 수 있습니다.
1. CPU Register
2. 미리 할당된 메모리 영역 (=data section)
3. 동적 할당된 메모리 영역 (=stack, heap section)
컴파일러가 프로그램을 컴파일 하면 프로그램 내에 포함되어 있는 정수와 문자열들은 하나의 데이터로 프로그램에 함께 포함되어 컴파일 됩니다. 해당 데이터에는 또한 미리 할당하기로 약속된 공간도 함께 보관됩니다.
0. 프로그램에 메모리가 할당되는 과정.
C언어 소스를 통해 프로그램에 메모리가 할당되는 과정을 살펴보도록 하겠습니다.
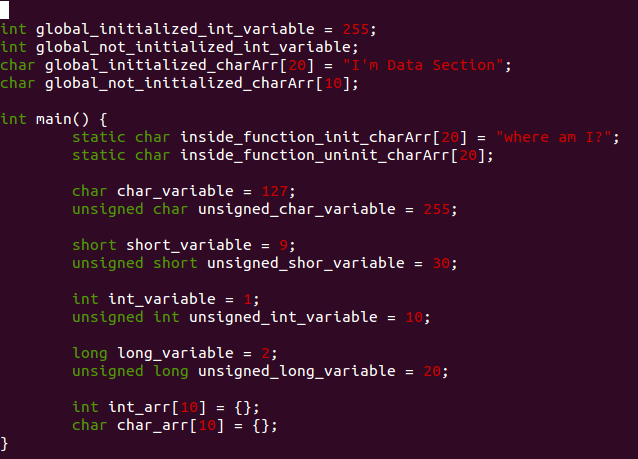
위의 소스에는 main이라는 함수 하나와 여러 변수들이 존재합니다. 먼저 함수는 SCOPE를 갖습니다. 이것은 어디부터 어디까지가 함수이냐? 의미하는 것인데, C언어의 경우 괄호() 이후 오는 중괄호 { } 가 함수의 SCOPE가 됩니다. 하나의 함수는 하나의 SCOPE를 갖고 SCOPE내에 변수들이 존재하게 됩니다.
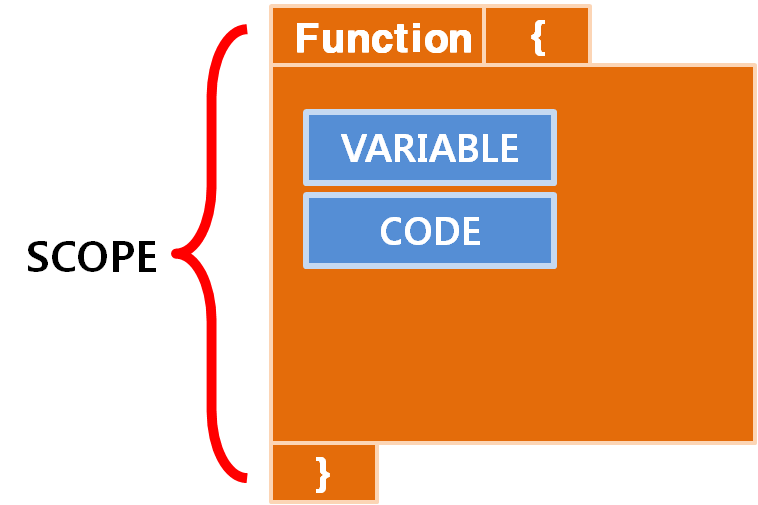
컴퓨터 공학과 수업 등을 통해 컴퓨터의 구조에 대해 조금 배우셨다면, 변수의 범위라고 해서 "지역변수는 Stack에 존재하고 Scope는 중괄호 안이고, 전역변수는 Data에 존재하고 범위는 프로그램" 같은 얘기를 들어보셨을 겁니다.
이런 수수께끼 같은 소리를 구체적으로 살펴볼 필요가 있습니다.
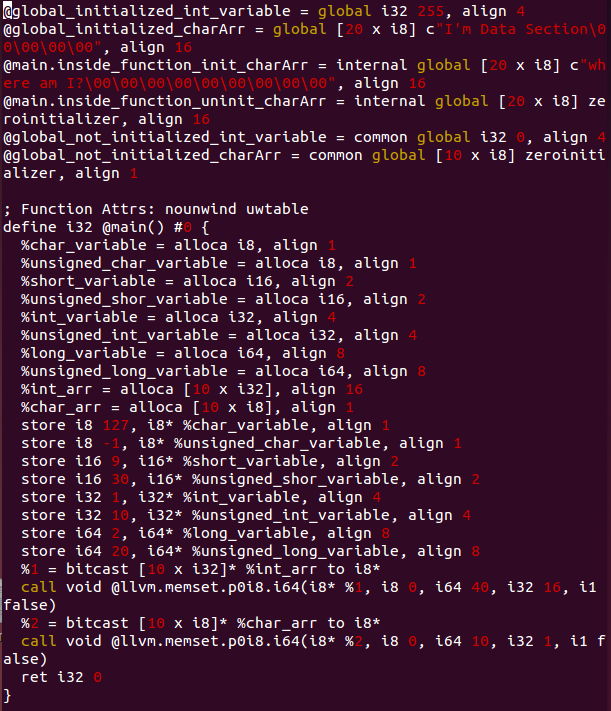
위의 IR을 보시면,
define i32 @main() #0 { ... } 으로 번역된 main 함수 내부에 변수들은, alloca로 시작됩니다. 이것은 allocation(할당)의 약자로 LLVM IR에서 메모리 공간을 할당하라는 키워드입니다. i는 bit수를 의미하죠. 그래서 %char_variable = alloca i8 의 뜻은 "char_variable에 i8=8bit를 할당" 을 뜻합니다. 이와는 대조적으로 global_로 시작하는 변수들과 static을 접두어로 선언한 전역변수의 경우 global로 선언되어 있는 것으로 볼 수 있습니다. internal, common과 함께 global이며, 해당 변수들은 alloca하지 않습니다. 이것은 공간을 할당하지 않는다는 뜻입니다.
store [대입 값], [대입 대상]
거듭 이야기 하듯 변수는 공간입니다.
하지만 함수 내에서 선언되고 사용되는 지역변수들에겐 메모리를 할당하지만 그렇지 않은 변수들은 메모리를 할당하지 않는 것을 알 수 있습니다. 이것은 함수의 정의와 함께 Stack을 사용하는 지역변수들의 특징과 관련되어 있습니다. 이에 대해서는 지난 글에서 다뤘습니다만 다시 한번 복기하자면, 함수는 일련의 연산과정을 여러 번 재사용하기 위해서 만들었습니다. f(x) = x+1 이라고 선언하면, 매번 x+1을 x+1로 기재할 필요 없이 f(x)라고 적으면 되는 것과 마찬가지 이야기 입니다. Stack은 이런 함수들이 매번 호출될 때마다 함수들의 연산과정 동안 사용할 메모리 공간을 마련하고 함수가 종료되는 시점에 해당 할당된 공간을 반환하는 자료 구조입니다.
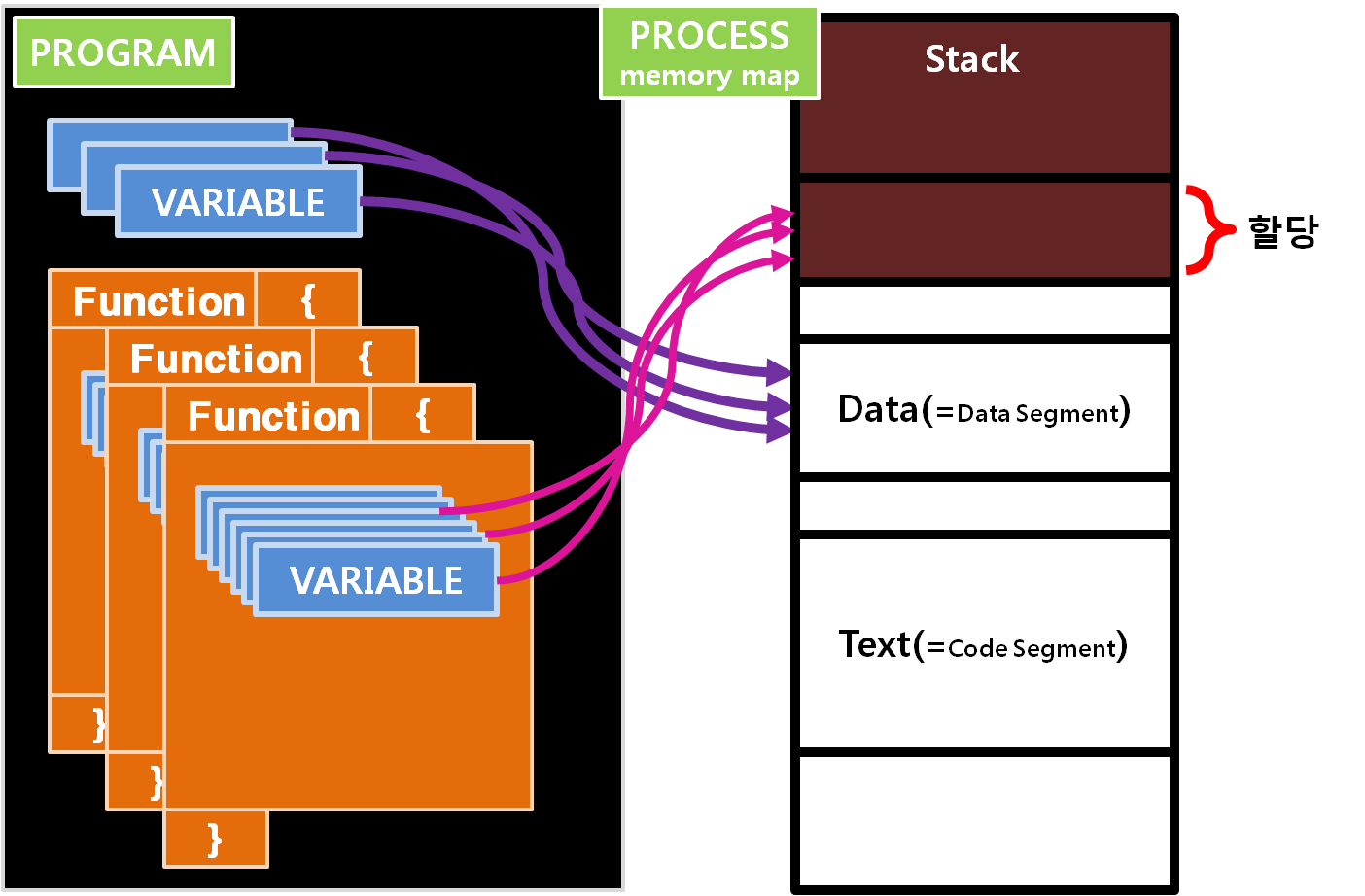
프로그램 내에서 전 프로그램에 걸쳐 사용될 전역변수들은 별도의 메모리 공간을 할당 받게 됩니다. 이와 다르게 함수의 지역변수는 실행 시에 Stack에서 메모리를 할당 받아 사용하게 되는 겁니다. 그래서 LLVM IR을 보면 alloca를 통해 할당 받은 후에 store를 통해 C언어 소스코드에서 초기화 한 값들을 Stack에 배정받은 공간에 입력하는 과정을 거칩니다.
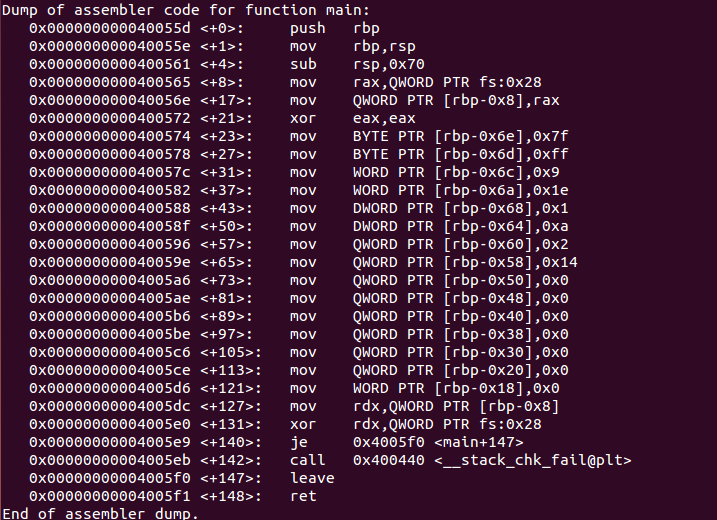
함수 내에서 Stack공간을 할당 받고, 해당 변수들에 값을 넣어주는 내용을 확인할 수 있습니다.
(더 자세한 내용은 지난 글을 참조해주세요.)

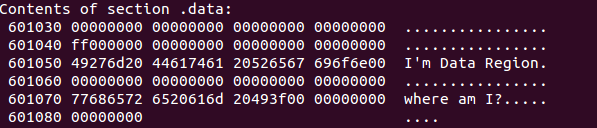
Data 영역에는 전역 변수와 함께 문자열들이 저장됩니다. 프로그램 자체는 하나의 파일이기에 Stack이나 Heap같은 메모리 공간이 없습니다. 그저 하나의 덩어리라고 생각하시면 됩니다. 여기에 추가로 운영체제에 따라 실행파일에 미리 넣기로 약속된 내용들이 포함되게 됩니다.

이런 프로그램을 사용자가 실행하여, 운영체제가 프로그램을 하나의 프로세스로 메모리에 적재하는 과정을 거치고 나면, 비로소 하나의 프로그램은 프로세스가 되어 실행되며 Stack과 Data영역에 메모리를 할당 받을 권한을 갖게 됩니다.
1. CPU Register
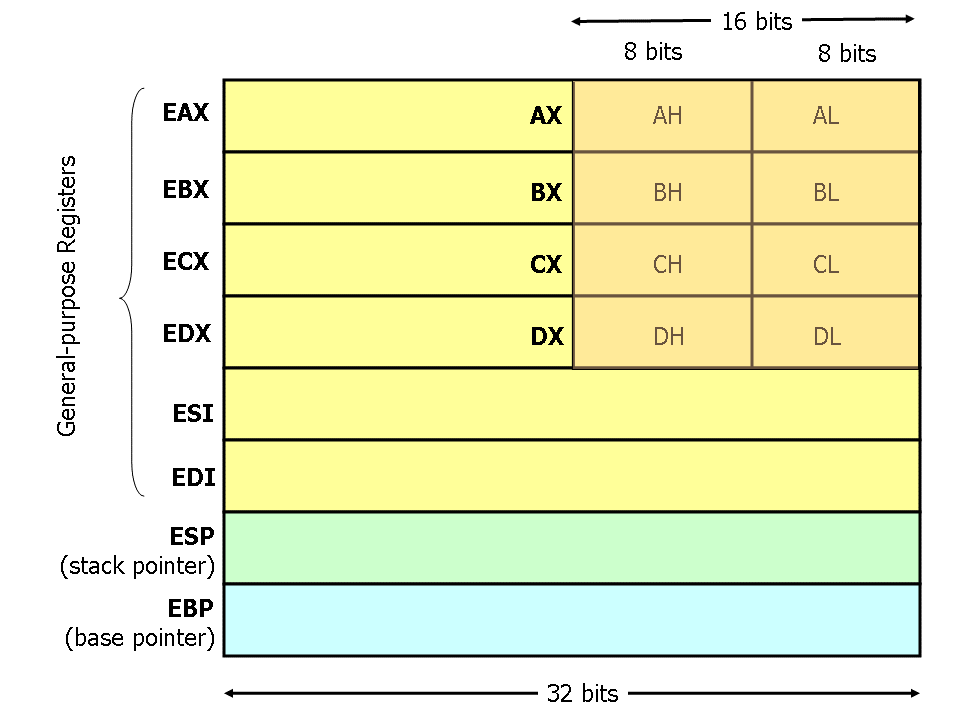
CPU의 Register 또한 하나의 변수를 저장하는 공간입니다. 컴파일러는 소스파일을 컴파일 할 때 CPU Register를 할당할 것인지 아닌지를 결정할 수 있습니다. 주로 하나의 값에 연관된 계산이 계속해서 이뤄진다고 한다면, A라는 값에 B, C, D, E, F를 순차적으로 더하는 상황처럼, A에 Register 하나를 할당하는 것이 전혀 아쉽지 않은 상황일 겁니다. 하지만 일반적으로 CPU Register에 변수를 할당하지 않는 이유는, CPU Register가 가장 빠름에도 불구하고 수가 적기 때문입니다. x86-32bit CPU는 단 6개의 레지스터만을 사용할 수 있습니다. 때문에 대부분의 컴파일러가 CPU Register에 변수를 할당하지 않습니다. 대신 변수가 연산을 거친 뒤 다시 메모리에 저장되기 전까지는 Register에서 추가 연산을 수행하기 때문에 변수로 사용되는 것과 같다고 생각하면 됩니다.
CPU에 할당된 변수는 레지스터의 이름을 가지고 접근하므로 EAX, AX, AH, AL 과 같은 방식으로 어셈블리어로 표현되게 됩니다.
2. 미리 할당된 메모리 영역 (=data section)
Data 영역은, 컴파일 된 프로그램 파일부터 할당되어 있는 영역입니다. 때문에 컴파일러가 프로그램을 컴파일 할 시에도 해당 섹션에 접근하는 것은 미리 할당되어 있는 메모리 주소로 접근하면 됩니다. 아주 쉽게 접근하고 사용할 수 있습니다. 보통 Data영역을 Disassembly하면 [DS:0x601038]과 같이 DS라는 Data Segment를 나타내는 약자가 붙는데, 현시대에 대부분의 컴퓨팅 환경에서 별 의미 없는 내용이고 0x601038 주소를 직접 접근하게 됩니다.

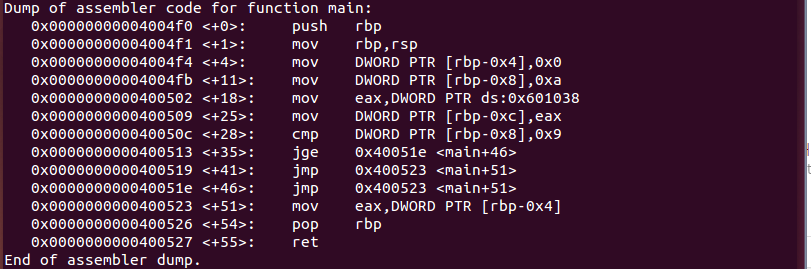
어셈블리어를 통해 int b에 전역변수 global 값을 대입하는 부분이 DWORD PTR ds:0x601038로 컴파일 된 것을 볼 수 있습니다.
3. 동적 할당된 메모리 영역 (=stack, heap section)
동적 할당된 메모리 영역은, Data영역에 접근하는 것처럼 미리 약속된 주소로 접근할 수 없기 때문에 실행 시에 지정된 주소로 접근하므로 좀더 복잡해집니다. 주로 동적 할당된 공간에 접근하는 방식은, 어떤 기준점 세우고 이를 기준으로 접근하게 됩니다.
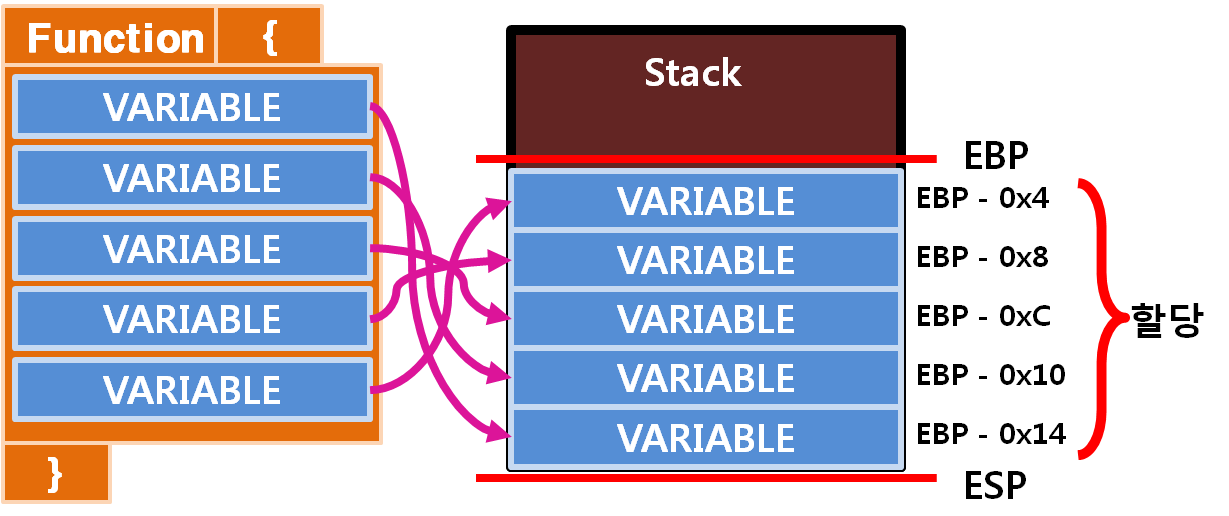
x86에서는 Stack Base Pointer가 CPU의 Register를 통해 제공됩니다. 이를 통해 각 프로그램들은 Stack의 Base를 기준화 할 수 있고, 각 함수 별로 Base Pointer를 이동시키는 것 만으로 Stack 공간을 할당하고 해제하는 것이 아주 쉽게 가능하다는 점은 전의 글을 통해 다룬 내용입니다. 첫 번째 변수가 Stack의 가장 아래 존재하는데, 함수 내 변수들은 Stack에 역순으로 정렬되기 때문이고 이것은 Stack의 특징이라고 할 수 있겠습니다.
4. 변수의 할당 방식에 따른 주소 지정 방식.
변수를 할당 방식에 따라 레지스터(=Register), 미리 할당된 영역(=Pre-Allocated Section), 동적 할당된 영역(=Dynamic-Allocate Section) 셋으로 분류했는데요, 간단히 이 세 유형의 변수들을 대표하는 기계어를 살펴보죠.
- 레지스터
CPU레지스터로, 변수를 메모리에서 레지스터로 로드한 뒤 필요한 연산을 수행하고 다시 메모리에 적재합니다.
레지스터에 값을 로드 : MOV EAX, [EBP-0x4]
레지스터에 값을 저장 : MOV [EBP-0x4], EAX
- 미리 할당된 영역
전역 변수라고 부르며 Data 영역 속하는 공간입니다..
변수 값을 레지스터로 로드 : MOV EAX, [DS:0x4009a0]
레지스터에서 변수로 저장 : MOV [DS:4009a0], EAX
- 동적 할당된 영역
지역 변수라고 부르며 Heap과 Stack 영역이 속하는 공간입니다.
레지스터에 값을 로드 : MOV EAX, [EBP-0x4]
레지스터에 값을 저장 : MOV [EBP-0x4], EAX
어떤 Base값을 기준으로 상대적 주소에 접근하는 방식을 상대주소지정 방식이라고 합니다.
ex) MOV EAX, [EBP-0x4], MOV EAX, [EAX+ECX+0x14]
미리 할당된 영역은 이미 주소가 정해져 있기 때문에 Base값이 필요 없죠. 이런 주소 지정 방식을 직접주소지정 방식이라고 합니다.
ex) MOV EAX, [DS:0x4009a0], MOV EAX, [0xA0A0A0A0]
5. +@와 요약
역공학에서, 변수는 수 많은 힌트들 입니다. 어떤 힌트는 원하는 방향으로 이끌어주지만 그러지 않은 경우가 더 많습니다. 그렇기에 자신만의 기준과 경험을 토대로 변수를 추적하는 노하우가 축적하는 것이 중요합니다. 일반적으로 연산 과정에서 변수는 Register 적재 되고, 연산 과정이 끝나면 다시 메모리 공간에 저장되거나 다른 변수로 대입되는 과정이 반복됩니다. 전역으로 선언된 변수는 프로그램 파일에 미리 할당된 영역에 존재하며 프로그램 내에서 Data Segment라는 의미의 DS가 붙는 메모리 주소로 접근하므로 알아보기 쉽습니다. 지역 변수는 프로그램이 적재되어 해당 지역변수가 있는 함수를 실행할 때 Stack의 Base Pointer를 이동시켜 확보한 Stack 메모리 공간을 할당 받고 활용되며 함수가 끝나는 시점에 마찬가지로 Base Pointer의 이동으로 메모리 공간이 해제되게 됩니다.
연산자
연산자는 수학에서 사용되는 더하기, 빼기, 곱하기, 나누기와 같은 수식과 추가로 =, *, ++, --, [] 같은 다양한 연산자가 있으며 "정해진 동작을 수행하도록 약속되어 있는 기호"입니다.
대부분의 연산자는 실제 CPU 명령어와 일치됩니다. 예를 들어, +는 add, -는 sub, << 는 shr 와 같은 명령어로 번역되게 됩니다. 이 글은 C언어를 배우자는 글이 아니므로 연산자를 어떻게 다루는지는 다루지 않을 겁니다. 대신 C에서 많이 사용되는 자료구조 구조체 struct와 포인터형 변수에 대해서는 살짝 맛을 보고 넘어가야 할 것 같습니다.
C의 연산자 중에 메모리 주소를 반환하는 연산자는 숫자가 들어가는 배열 선언 연산자(ex: name[20])과 포인터 연산자(ex: int* ptr), 그리고 구조체의 접근 연산자 마침표(ex: me.name )가 있습니다. 이런 연산자들이 사용되는 경우 기존의 변수와는 접근 방식이 달라지기 때문에 유의해야 합니다.

배열을 토대로 이를 이해해보면 어떨까 싶습니다.
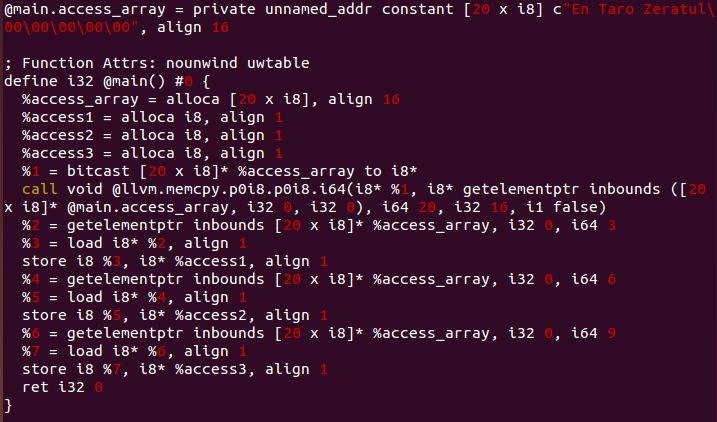
LLVM은 Char access_array[20]에서 3, 6, 9번째 값을 대입하는 코드를 위와 같이 번역합니다.
이 중에 3번째 배열 요소에 접근하는 경우를 골라 살펴보겠습니다.
%2 = getelementptr inbounds [20 x i8]* %access_array, i32 0, i64 3
%3 = load i8* %2, align 1
store i8 %3, i8* %access1, align 1
access_array의 3번째 주소를 선택하는 구문으로 getelementptr을 사용합니다.
이 값을 access1에 저장하는 store를 사용하는 것으로 마무리 됩니다.
앞서 변수는 (메모리)공간에 존재하고, 모든 변수는 접근하기 위한 기준이 있으며, 지역 변수의 경우 Stack Base Pointer를 사용하는 컴퓨터 구조 원리를 설명했습니다. 이와 비슷하게 주소 지정 방식을 사용하는 변수들이 있습니다. 주소 지정 방식을 사용하는 경우는 Stack Base Pointer를 사용할 수 없는 상황인 동적 할당한 공간, 구조체, 배열과 같이 자체적인 기준점을 기반으로 접근해야 하는 경우가 있기 때문입니다.
Char access_array[20] 에서 변수 명 뒤에 붙는 []는 Char형 변수를 20개만큼 연달아 만들라는 연산자입니다. 해당 공간에 실제적인 접근을 하는 방법은 access_array의 주소를 기반으로 변수 형인 Char=1byte 만큼 증가시켜가며 공간에 접근하게 됩니다. 포인터 변수와 포인터 연산자 뿐 아니라 구조체 변수 또한 동일한 방식의 접근 지정을 하게 됩니다.
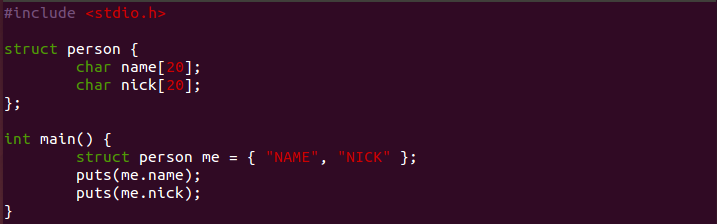
struct:구조체는 사용자 정의 변수입니다. 기본적으로 제공하는 변수형을 묶어서 새로운 변수형을 만드는 기능을 제공합니다.
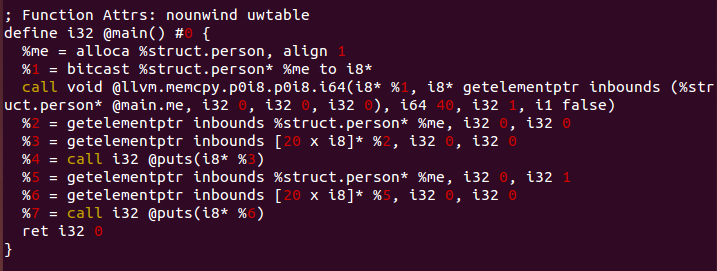
번역된 IR 중에 name을 출력하는 부분만 한번 볼까요?
%2 = getelementptr inbounds %struct.person* %me, i32 0, i32 0
%3 = getelementptr inbounds [20 x i8]* %2, i32 0, i32 0
%4 = call i32 @puts(i8* %3)
getelementptr inbounds는 element의 주소 값을 자체적인 기준점을 기반으로 주소를 지정하는 키워드입니다. 그래서 위의 IR은 구조체 person인 me를 기준으로 0번째 element인 name과 1번째 element인 nick 중에 0번째 element인 name배열을 지정하는 주소 값을 얻어와 출력을 해주는 구문이 됩니다.. 앞서 배열을 통해 배열의 요소에 접근하는 방식과 똑같은 방식입니다.
다시 한번 포인터를 통해 자체적인 기준점을 기반으로 주소를 지정하는 방식으로 변수에 접근하는 경우를 볼까요?
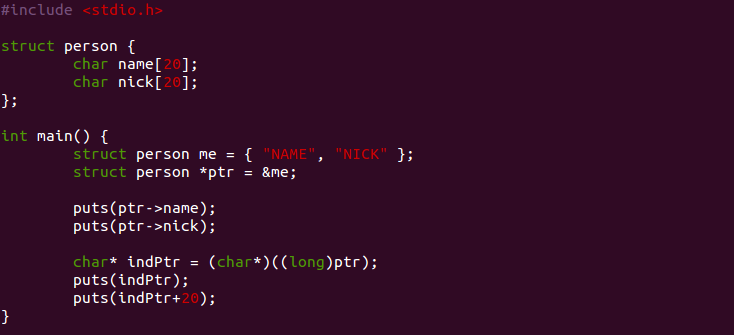
이 C 소스코드는, struct person 변수 me를 pointer 연산자 * 를 통해 pointer형 변수 ptr을 통해 접근하는 방식을 표현하고자 했습니다.
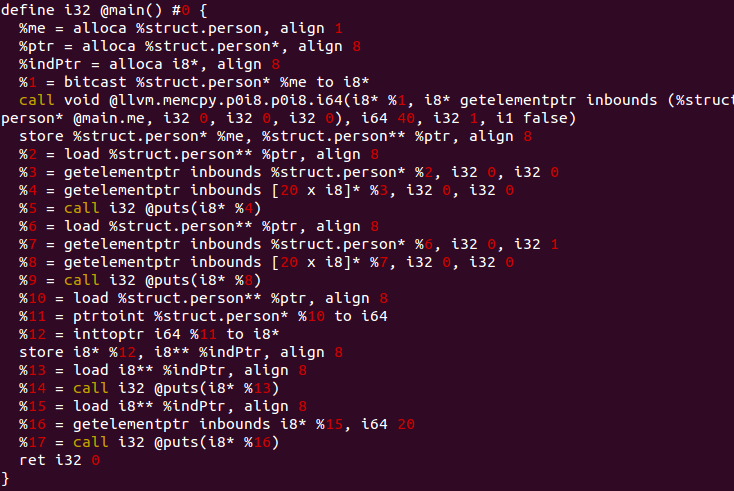
역시 번역된 IR 을 통해 살펴보죠.
%6 = load %struct.person** %ptr, align 8
%7 = getelementptr inbounds %struct.person* %6, i32 0, i32 1
%8 = getelementptr inbounds [20 x i8]* %7, i32 0, i32 0
%9 = call i32 @puts(i8* %8)
위의 부분은 ptr->nick으로 연산자 "->"를 사용해 struct person의 nick을 지정하는 구문을 옮긴 것입니다.
이를 어떻게 번역했는지는 상당히 중요하니, 다시 한번 복기하면 좋을 것 같습니다.
1. struct person의 주소를 지정하는 ptr을 먼저 로드하고
2. ptr주소를 기반으로 일정 주소를 뛰어 name 이후 nick의 주소를 지정
하게 됩니다.
이후 indPtr은 ptr이 지정하는 주소를 직접 받아와 직접 char 배열 name의 크기만큼 더해줘서 다음 요소 nick의 주소를 지정했습니다.
%15 = load i8** %indPtr, align 8
%16 = getelementptr inbounds i8* %15, i64 20
%17 = call i32 @puts(i8* %16)


실제로 둘이 컴파일 된 결과를 보면 차이가 없죠?
연산자의 요점을 정리하자면, 대부분의 연산자는 기계어와 1:1 매치가 된다. 주소지정을 하는 연산자인 배열[]연산자, 포인터*연산자, 구조체 변수가 어떤 방식으로 동작하는지 이해하는 것은 굉장히 중요하다. 왜냐면, 변수는 모두 메모리의 공간이고, 해당 주소에 접근하는 방식으로 변수를 다루기 때문이다. 또한 후에 더 복잡하게 이중 삼중으로 참조되는 변수를 추적하기 위해서라도 기초적인 부분을 제대로 이해하고 가는 것이 중요합니다.
함수
함수는 수학에서 사용되는 함수 f(x)와 같이, "연산자로 정의되지 않은, 연산과정을 수행하도록 만들 수 있는 사용자 정의 연산자" 입니다. 함수는 컴퓨터공학에서 말하는 Code Section 혹은 Code Segment에 존재하게 됩니다.
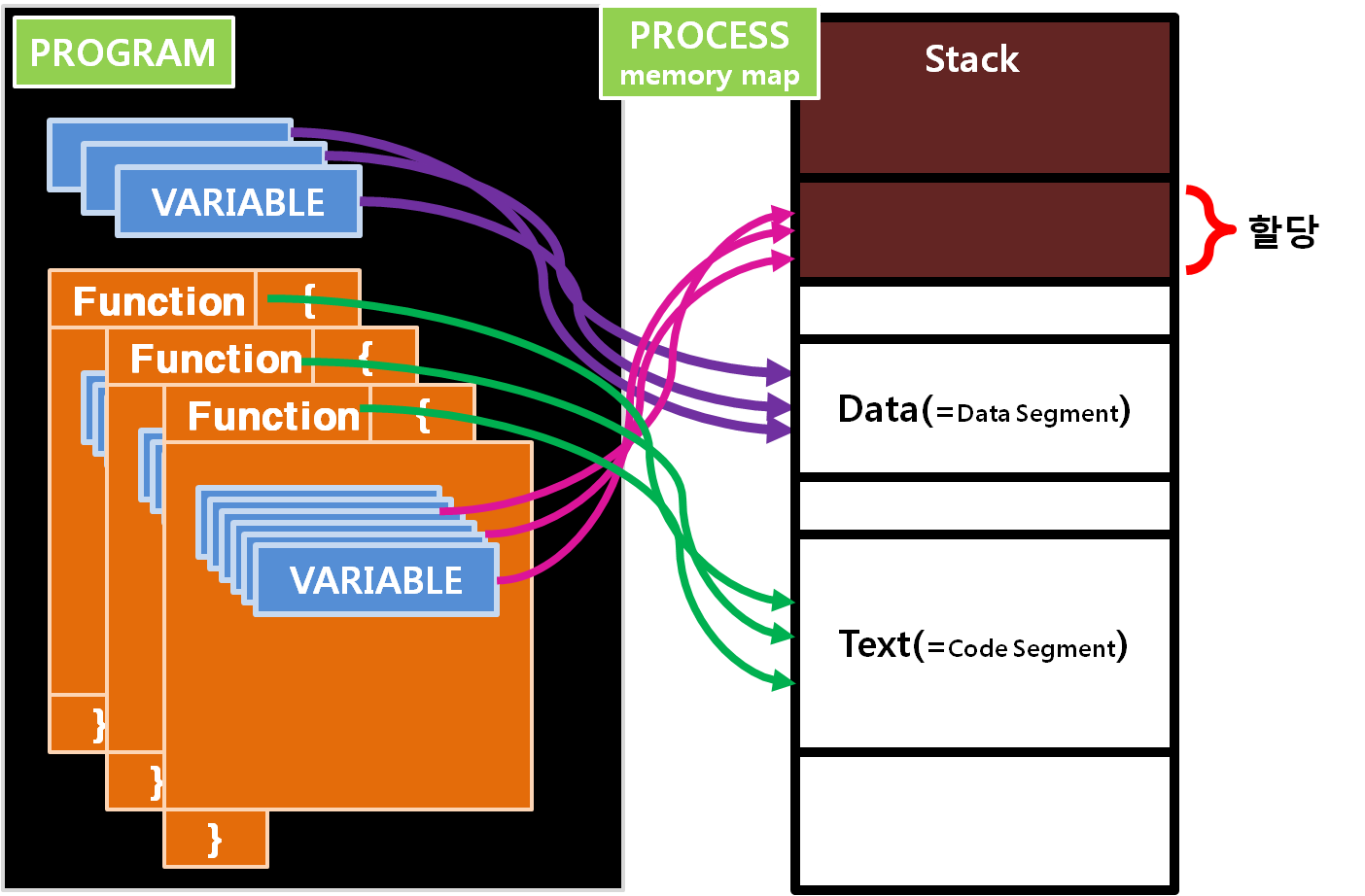
모든 프로그램들은 함수로 시작해서 함수로 끝납니다. 그러므로 함수를 설명하자면 Main함수에 대해 집고 넘어가지 않을 수 없습니다. Main 함수는 프로그램의 시작과 끝, 알파이자 오메가니까요. Main 함수를 지칭하는 다른 말로 "진입지점 : Entry Point"라고 합니다. 모든 함수는 다른 함수에 의해서 호출 받게 되어 있습니다. 그런 의미에서 진입지점이란 뜻은, 운영체제에 의해 프로그램이 Load된 후 실행하기 시작하는 시점이라는 뜻입니다. 즉, 운영체제에 의해 Main 함수가 프로그램에서 최초로 호출되게 되는 겁니다.
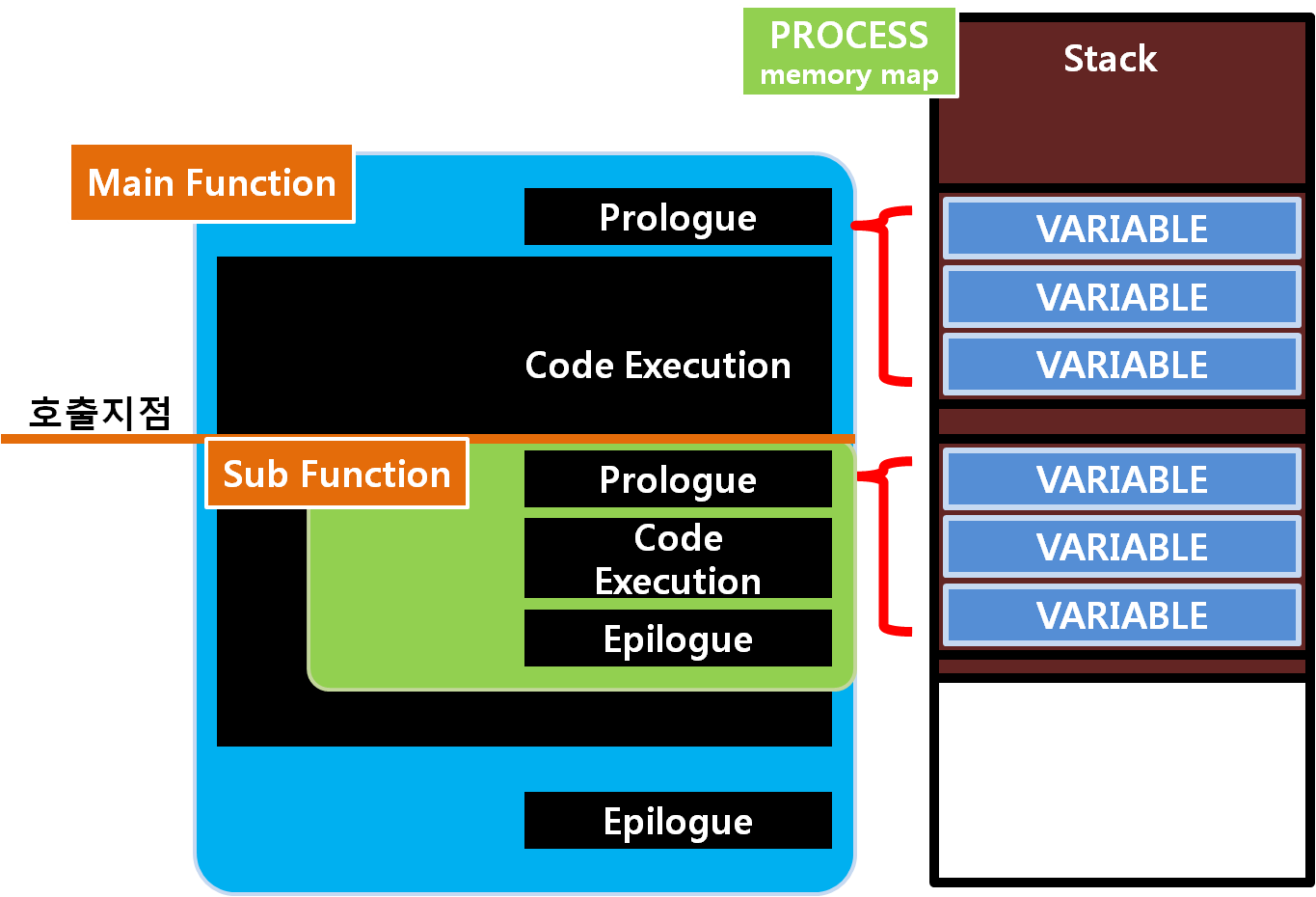
함수는 프롤로그와 에필로그가 포함됩니다. 각 프롤로그는 Stack에 지역변수에서 사용하는 만큼의 공간을 확보합니다.
보통 아래와 같은 형식을 갖습니다.
push ebp
mov ebp, esp
sub esp, (스택사이즈)
그리고 에필로그는 함수를 끝내며, 확보했던 Stack공간을 반환하고 함수를 호출하며 Stack에 넣어둔 복귀 주소로 돌아가 새롭게 코드를 수행하게 됩니다.
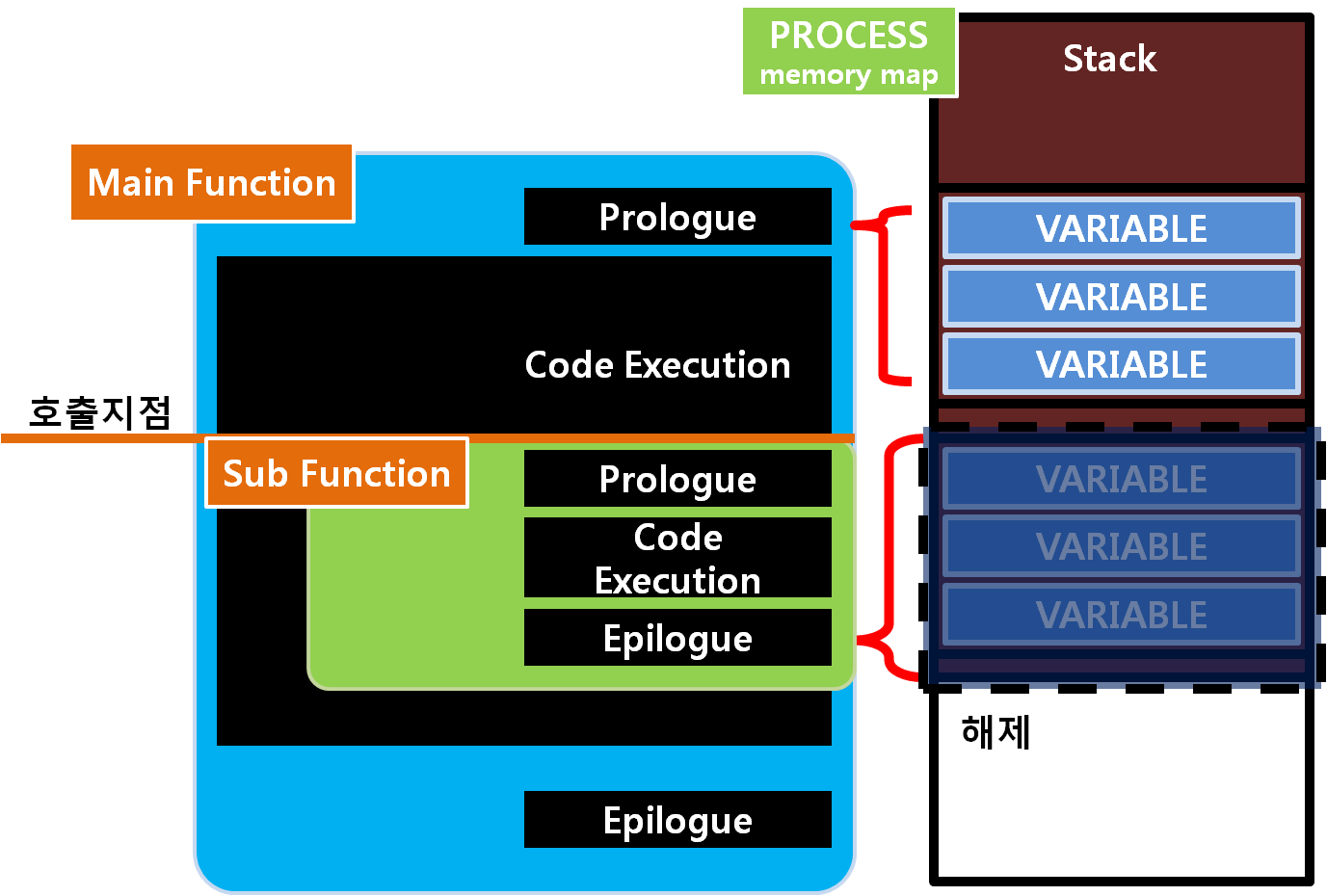
이후 호출될 때의 상태로 복귀해 코드 실행이 계속 되게 됩니다.
이에 대한 자세한 설명은 바로 전의 글을 참고해주세요.
C++ 언어 뒤집어 생각하기.
객체지향과 클래스( Object-Oriented Programming And CLASS)
C++에서는 객체지향 개념이 도입되어 Class라는 새로운 변수형이 생깁니다. 변수의 중요성은 더 이상 언급할 필요가 없을 것 같습니다, 객체지향으로 프로그래밍 된 프로그램은 거의 모든 변수가 클래스로 이루어져 있으므로 이에 대한 이해가 거의 필수나 마찬가지입니다. 그럼 그 클래스의 구조와 설계 원리를 살펴볼까요?
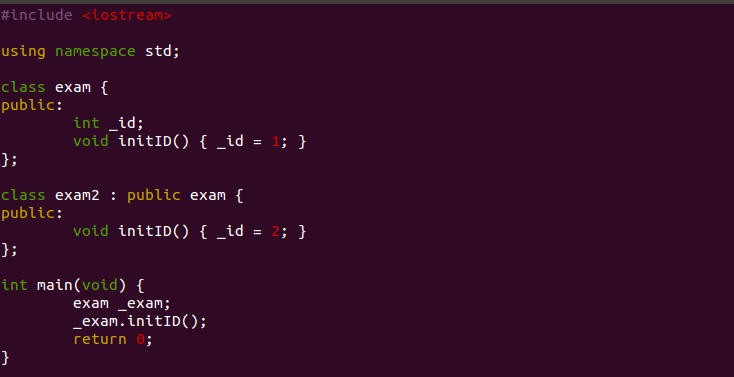
클래스는 C언어의 구조체와 비슷하게 다양한 변수형을 묶어 사용자 정의 변수형을 만들 수 있는 틀을 제공합니다. 클래스는 C언어의 구조체에서 한 발 더 나아가 변수들의 묶음인 구조체에 추가로 변수들을 다루고 조작하는 함수들도 함께 묶습니다. 위의 소스코드는 변수 _id와 _id에 값을 넣는 initID() 함수를 함께 묶은 exam이라는 클래스를 선언했습니다. 이처럼 클래스 내부에서 선언되는 변수와 함수는 '멤버'를 붙혀, 멤버 변수, 멤버 함수라고 지칭합니다. 우리가 여기서 C++ 문법을 배우자는 건 아니니 구체적인 설명은 하지 않겠습니다. 다만, 클래스도 그간 학습해 온 기본적인 구조를 기반으로 하기 때문에 크게 달라지는 건 없다는 점을 주지하시면 됩니다.
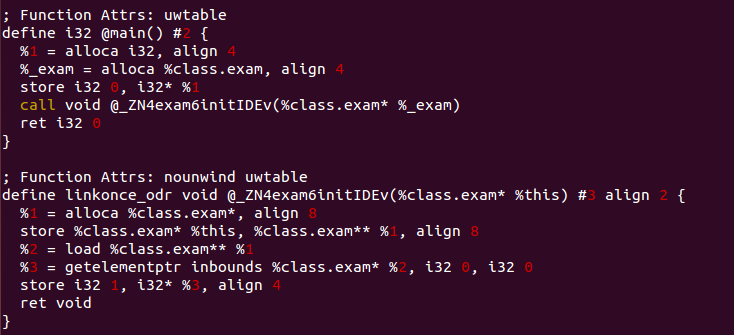
즉, 클래스도 지역 변수로 선언되면 Stack에 위치합니다. 또한 클래스의 멤버 함수 또한 Text영역에 위치하게 되죠. 여기까지는 크게 달라지는 건 없습니다. 나머지 부분은 어떨까요? 함수까지 오면 차이점이 조금 보이게 됩니다.
call void @_ZN4exam6initIDEv(%class.exam* %_exam)
exam의 멤버함수인 initID()를 호출하는 부분입니다. initID() 함수는 아무런 인자 값을 받지 않음에도 불구하고 클래스 exam 변수 _exam의 주소 값을 넘겨주시는 걸 볼 수 있습니다. 그리고 해당 주소 값을 this라고 저장하는 것을 볼 수 있습니다. 이것은 객체지향에서 'This Pointer' 로 부르는 클래스 자기 자신의 주소 값을 저장하고 있는 변수입니다.
%2 = load %class.exam** %1
%3 = getelementptr inbounds %class.exam* %2, i32 0, i32 0
store i32 1, i32* %3, align 4
본래 initID() 함수는 그저 _id라는 멤버 변수에 1의 값을 넣어주는 간단한 멤버함수 입니다. 그리고 위의 IR은 그 부분을 나타내고 있습니다. 거듭 반복되는 말이지만 변수는 공간입니다. 메모리든, 파일이든 어딘가에 존재하는 공간이고 따라서 변수를 다루기 위해서는 주소를 지정해야 한다는 점을 분명히 해야 합니다. 그게 Stack에 존재하는 지역변수이든, 전역변수이든, stack, data, heap 어느 영역에 존재하든 마찬가지 입니다. 그리고 그런 변수들에 접근하기 위해서는 주소를 통하게 됩니다.
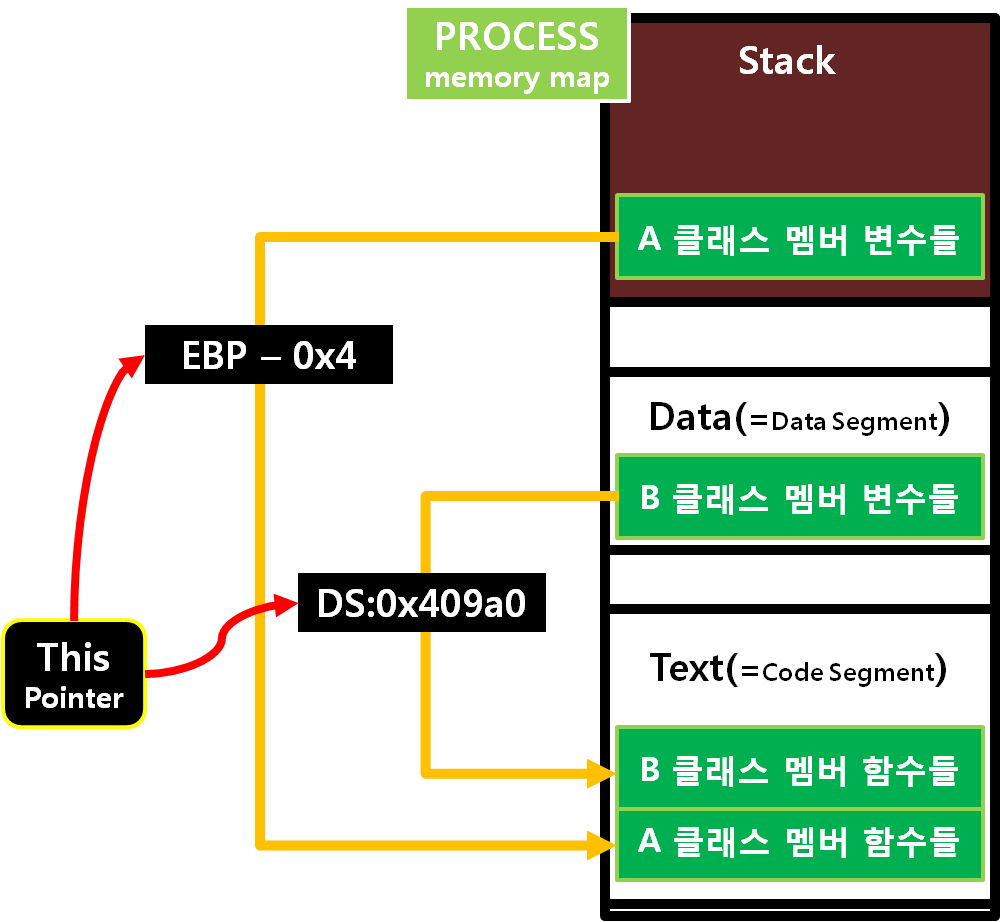
클래스의 멤버 함수들은 멤버 변수들에 대한 접근이 자유롭도록 설계되었습니다. 그런 설계 특성상 클래스의 멤버 변수와 멤버 함수를 연결하는 결합 부(=인터페이스 Interface)가 필요하게 됐는데 그게 바로 'This Pointer"입니다. 이에 따라 위의 IR을 이해하고자 하면, 멤버 함수에서 인자 값으로 지정하지 않더라도 필수적으로 넘어가게 되어 있는 'This Pointer'를 통해 멤버 변수 _id에 접근하여 1의 값을 저장한다고 이해할 수 있습니다.
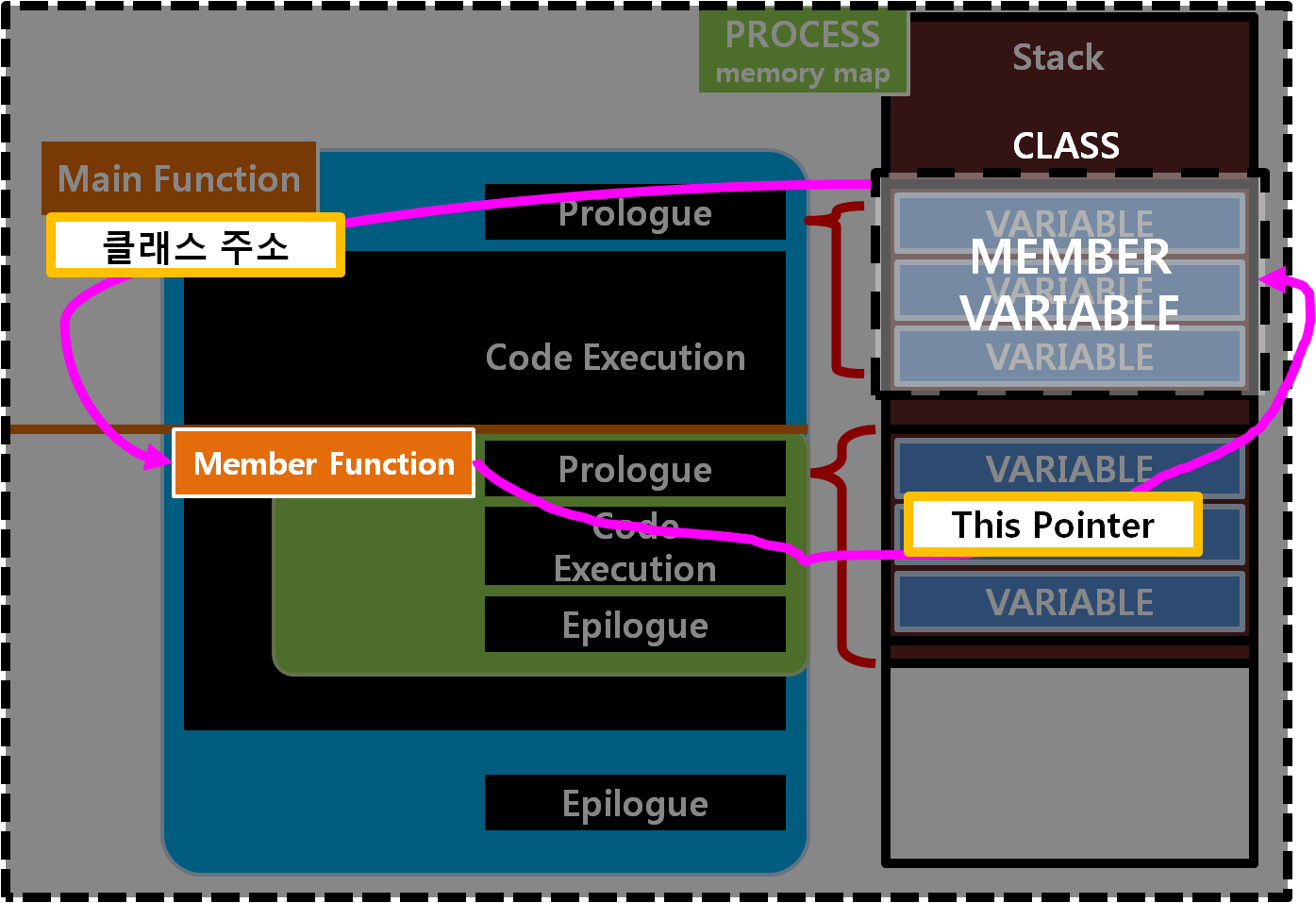
객체지향에서는 Dynamic-binding 혹은 Lately-binding이라고 부르는 새로운 문법이 등장하게 되는데요. 이 문법은 굉장히 특이하면서 중요하기도 합니다. 일단, 객체지향과 클래스는 C++이후 등장하는 거의 모든 객체지향 프로그래밍 언어에 기반이 되는 설계구조입니다. 중요하겠죠? C++에서 동적바인딩(=Dynamic Binding)이란 객체지향의 문법적 표현은, 프로그램이 구동되고 있는 시기, 그 상황에 맞춰 실시간으로 사용할 함수를 설정해서 사용할 수 있는 기능을 제공합니다.
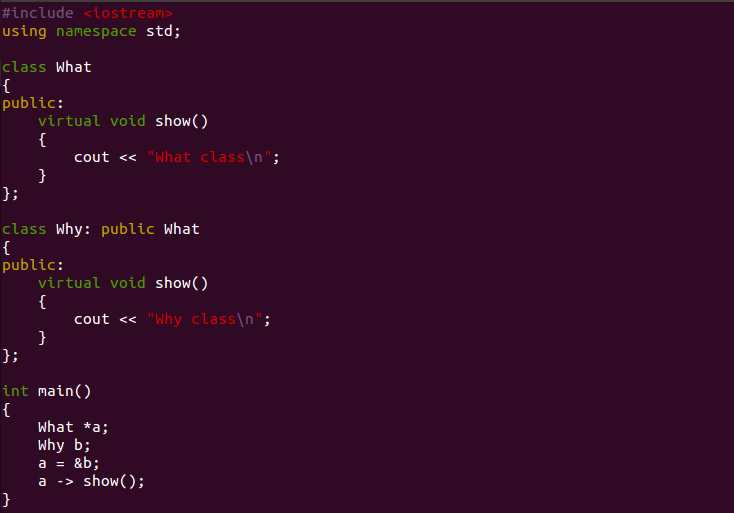
C++소스를 하나 보시죠. 여기서 virtual 이라고 선언된 함수가 바로 동적 바인딩의 대상이 되는 함수입니다. virtual 키워드가 붙으면 가상이라는 접두어가 추가되어 여기서 show는 가상멤버함수라는 명칭이 됩니다.
클래스는 멤버 변수와 함수로 이루어져 있습니다. 고로 What이란 클래스의 show()라는 함수는 What의 show()가 되고, Why 클래스의 show()는 Why의 show()가 되죠. 이를 편의상 What.show() 와 Why.show()라고 지칭하겠습니다. 그렇다면 What의 형으로 선언된 a라는 클래스 포인터가 호출하는 show()는 What의 show()가 되는 것이 일반적입니다. 하지만 이번에는 그렇지 않습니다. virtual의 선언적 의미는 "What의 클래스에 속했다고 해서 What의 show()라고 정의하지 않겠다. " 입니다. 즉, 컴파일 시에 해당 함수를 호출하도록 미리 정의하지 않고 실행 간에 어떤 함수를 호출할지 정하겠다는 뜻입니다.
이것이 어떻게 가능하냐? 그 전의 함수 호출은 컴파일러에 의해 기계어로 번역되는 시점에 주소를 결정하고 해당 주소를 호출하는 방식으로 결정됩니다.
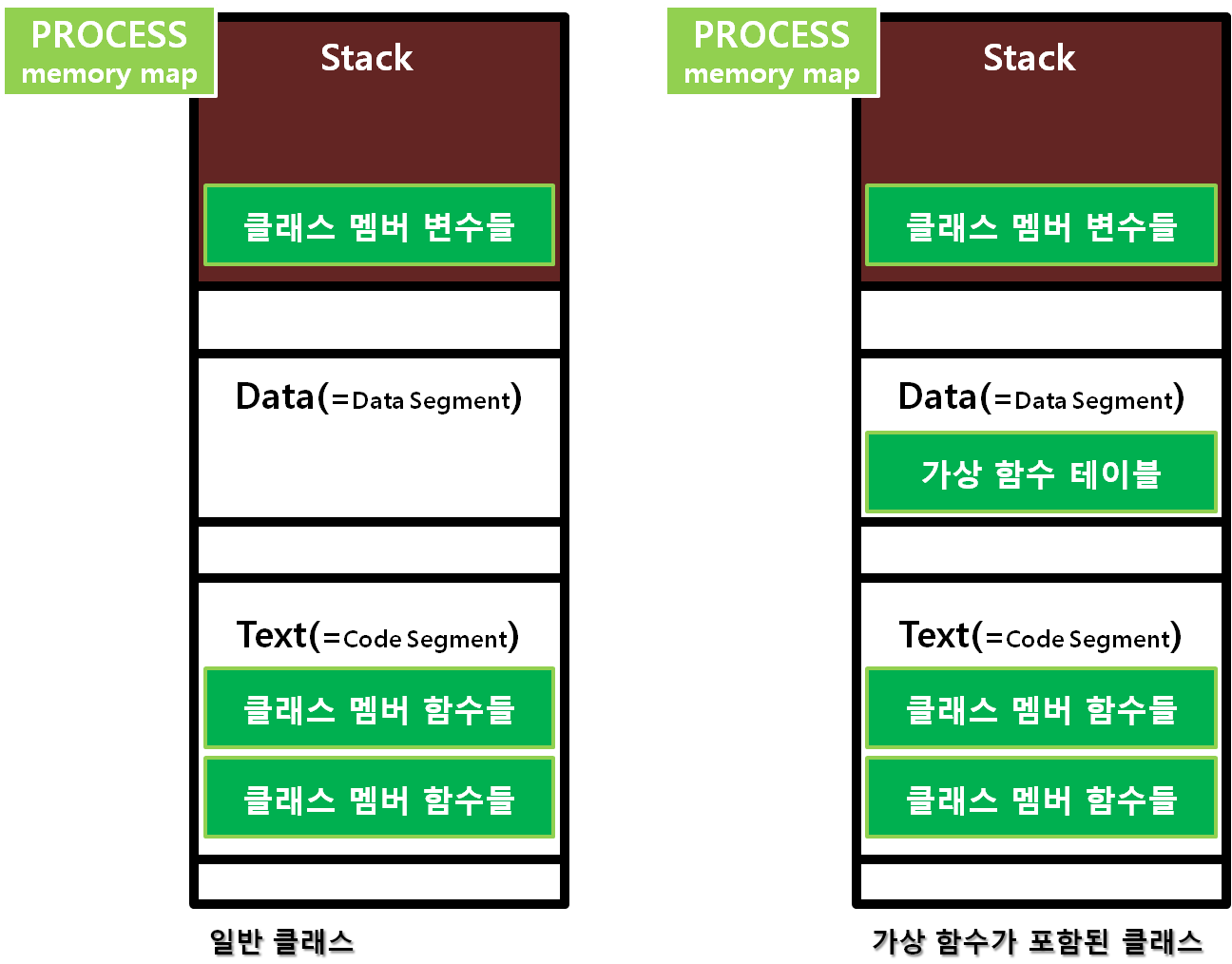
이를 C++ 이후 객체지향에서는 호출할 주소를 미리 정하지 않고 대신 실행 시에 주소를 넣어주도록 되어있는 가상함수 테이블이란 공간을 만들어 두고, 해당 테이블을 참고해서 호출하도록 기계어로 번역합니다. 이런 설계의 결과로 프로그램은 실행 시에 다양한 클래스와 다양한 함수간의 다수 대 다수 매칭을 성립시키는 겁니다. 결과적으로, 위의 코드에서 a는 b의, 즉 What.show()를 호출하지 않고 Why.show()를 호출하게 됩니다. What형 *a 변수로 선언되었음에도 불구하고 Why형 변수 b의 why.show()를 호출하게 되는 것이죠.
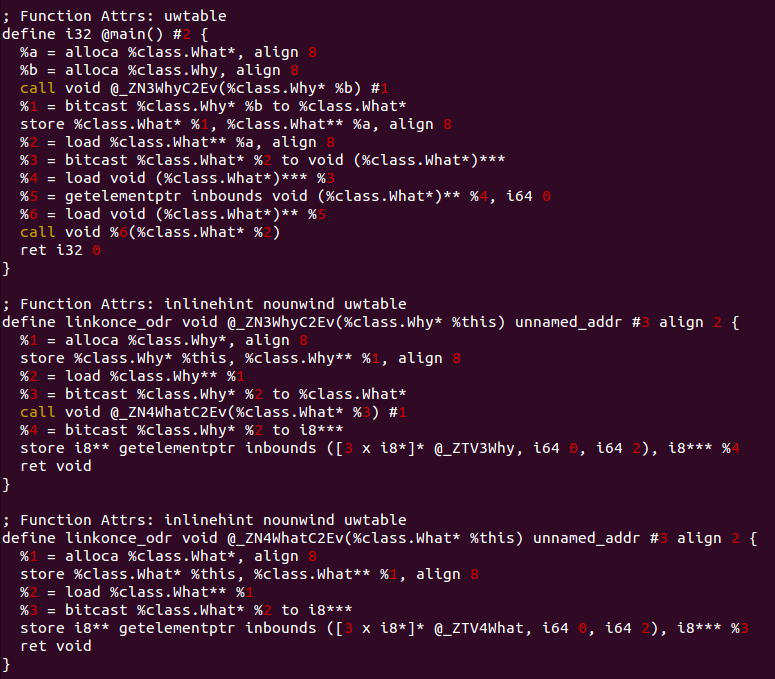
자 다시 IR로 넘어가서 살펴보도록 하겠습니다. IR에는 우리가 코딩하지 않은 구문이 굉장히 많이 보입니다.
한번 동일 클래스에서 virtual만 뺀 소스의 IR과 비교해보시죠.
동일한 부분이 변수를 선언하는 부분이라고 하면, 남는 부분이 virtual과 연관된 부분일겁니다.
이를 둘로 나눠서 살펴보도록 하겠습니다.
1. Virtual 함수가 있을 때 추가되는 함수.
Virtual 함수가 없는,
%b = alloca %class.Why, align 1
%1 = bitcast %class.Why* %b to %class.What*
과 Virtual 함수가 있는,
%b = alloca %class.Why, align 8
call void @_ZN3WhyC2Ev(%class.Why* %b) #1
%1 = bitcast %class.Why* %b to %class.What*
둘을 두고 비교해보면 함수가 하나 추가되어 있음을 볼 수 있습니다.
call void @_ZN3WhyC2Ev(%class.Why* %b) #1
요 녀석이 참조할 가상함수 테이블의 주소를 지정해주는 역할을 합니다.
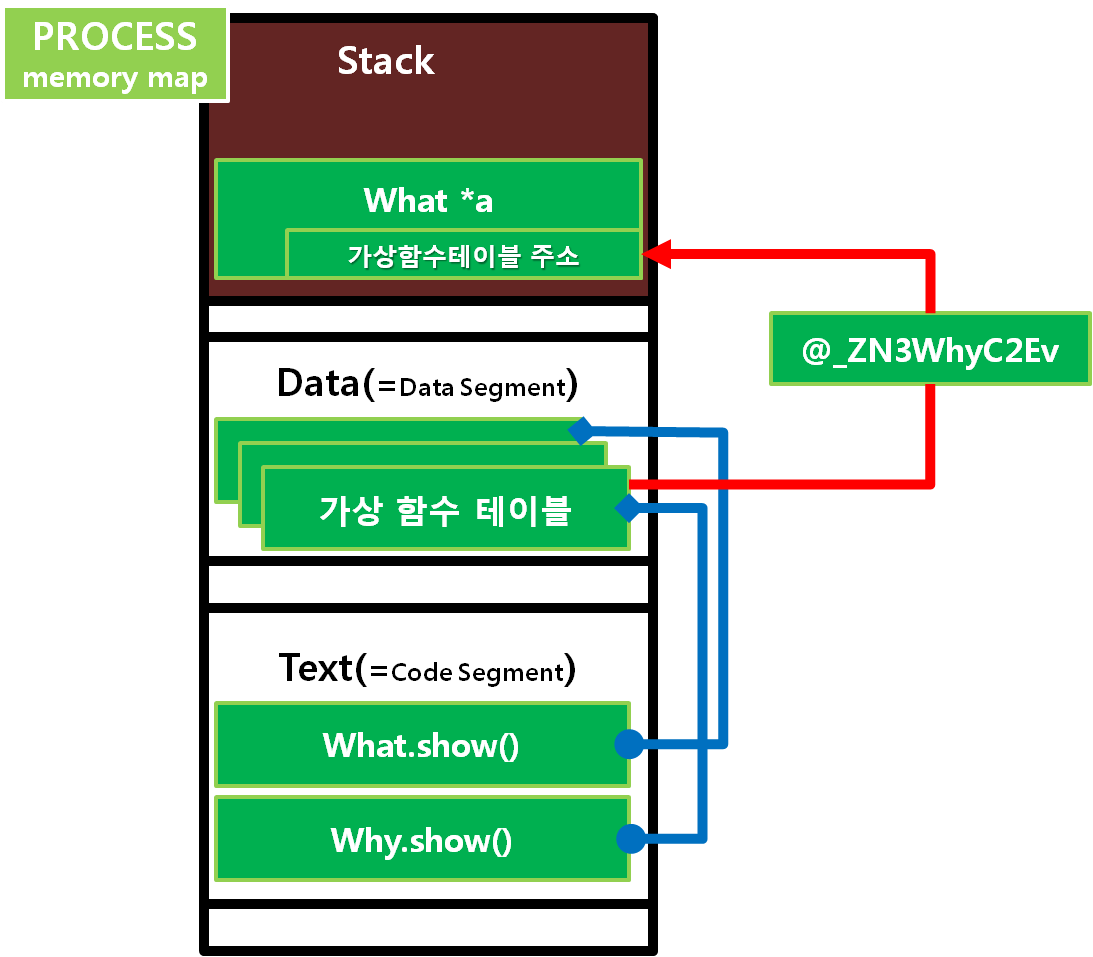
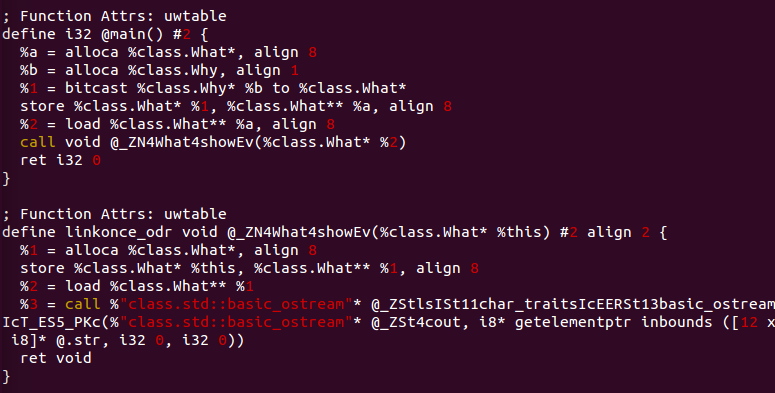
2. Virtual 함수를 호출할 때 추가되는 IR
%3 = bitcast %class.What* %2 to void (%class.What*)***
%4 = load void (%class.What*)*** %3
%5 = getelementptr inbounds void (%class.What*)** %4, i64 0
%6 = load void (%class.What*)** %5
요것은 가상함수 테이블에서 호출할 함수의 주소를 읽어오는 구문이지요.
가상함수 테이블에 있는 show() 함수의 주소를 꺼내와 호출하게 됩니다.
주목해야 할 것은, call void @_ZN4What4showEv(%class.What* %2)에서는 What.show()를 직접 호출했었는데, What.show()에 virtual 키워드를 추가해 가상 함수로 선언하면 call void %6(%class.What* %2)으로 %6. 즉, What클래스의 show() 함수가 위치하는 공간의 주소 값을 읽어와 해당 주소 값을 호출한다는 겁니다. 이것이 앞서 설명한 가상함수 테이블(Virtual Function Table)을 참조해 함수를 호출하는 것을 나타내는 것 입니다.
'Study' 카테고리의 다른 글
| Control Flow Integrity for COTS Binaries (0) | 2023.02.04 |
|---|---|
| Class linking 메커니즘 - jvm (0) | 2022.09.30 |
| [C] 다른 문자 위치 찾기 (0) | 2019.11.17 |
| git 복구 (0) | 2019.09.25 |
| git 계정 설정 (0) | 2017.12.17 |


