
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- linux thread
- v8 optimizing
- tracing
- uftrace
- LLVM Obfuscator
- so inject
- LLVM 난독화
- TLS
- Obfuscator
- v8 tracing
- Linux packer
- tracerpid
- linux debugging
- 난독화
- LLVM
- OSR
- initial-exec
- android inject
- anti debugging
- Android
- thread local storage
- Injection
- custom packer
- pinpoint
- on stack replacement
- apm
- pthread
- Linux custom packer
- 안티디버깅
- on-stack replacement
- Today
- Total
Why should I know this?
ART-Compiler] LoopOptimizing #1 본문
AOSP 에서 ART 라고 불리는 Android runtime은 DEX Bytecode를 Compile 하는 기능이 포함되어 있습니다.
해당 Compile에는 Optimizing 도 포함되어 있으며 이 글은 LoopOptimizing을 살펴보고자 작성했습니다.
최적화는 매우 어렵운 분야라는 생각이 있고 실제로도 그렇지만 LoopOptimizing 은 얕게 보면 이런것도 최적화야? 라는 생각이 들게 합니다. 그만큼 입문으로 좋지 않을까 하네요?!
ETRI에서 낸 PAPER중에 Static Dalvik Bytecode Optimization for Android Applications 이 있습니다.
이 논문에서는 DEX bytecode를 LLVM IR로 변환하여 Loop 최적화를 하는 과정을 소개하고 있습니다.
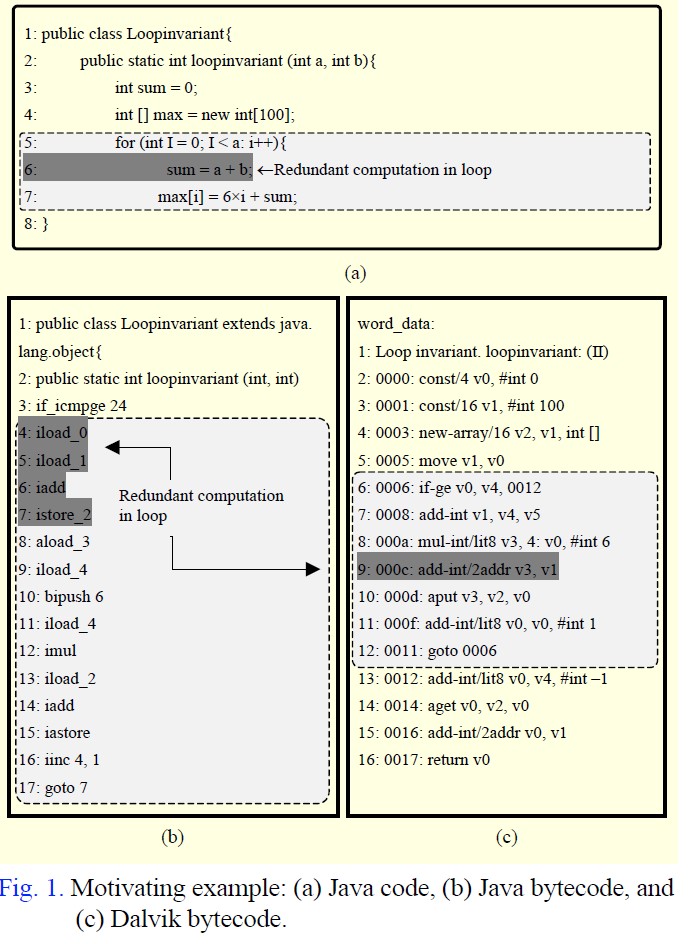
위 논문은 2015년 소개되었고 ART 에는 v8 에서 따온 Bytecode 관련 최적화 pass들이 2016년 추가됩니다.
2016년이면 AOSP 버전 7.1 입니다.
잡설이지만 DEX가 생성되는 과정은, 먼저 Java Code를 .class로 컴파일 한 뒤 .class 파일들을 aggregate해서 .dex를 생성하게 됩니다. 그러므로 만약 gradle을 통해 java code로 생성된 .class 파일을 대상으로 최적화를 진행하는 plugin을 개발했었다면 AOSP 5~7 까지는 사용할 수 있었을 것 같습니다.
아주 간단한 loop optimization이 추가됐고 벤치로는 73x 빨라지는 경우가 있다고 합니다.
"Speedup on e.g. Benchpress Loop is 73x (17.5us. -> 0.24us.)"
아래는 관련 링크입니다.
https://android-review.googlesource.com/c/platform/art/+/271392
https://android-review.googlesource.com/c/platform/art/+/271392
android-review.googlesource.com
loop optimization의 첫 머지 링크입니다.
첫 구현버전은 두 가지 최적화를 담고 있습니다.
1. 빈 루프 제거
2. simplify induction
첫 커밋에는 비교적 간단한 구현만 들어있어서 더 이해하기 쉽습니다.
// Simple case, the induction is only used by itself. Although redundant,
// later phases do not easily detect this property. Thus, eliminate here.
// Example: for (int i = 0; x != null; i++) { .... no i .... }
if (phi->GetUses().HasExactlyOneElement()) {
// Remove the cycle, including all uses. Even environment uses can be removed,
// since these computations have no effect at all.
RemoveFromCycle(phi); // removes environment uses too
RemoveFromCycle(addsub);
continue;
}
주석처럼 for (int i = 0; x != null; i++) { .... no i .... } 같은 코드가 있다면 해당 블럭에서 i를 증감시키는 코드와 i 와 관련되 생성된 PHI 노드의 제거가 가능해지므로 이를 제거하는 코드입니다.
// Closed form case. Only the last value of the induction is needed. Remove all
// overhead from the loop, and replace subsequent uses with the last value.
// Example: for (int i = 0; i < 10; i++, k++) { .... no k .... } return k;
if (IsOnlyUsedAfterLoop(*node->loop_info, phi, addsub) &&
induction_range_.CanGenerateLastValue(phi)) {
HInstruction* last = induction_range_.GenerateLastValue(phi, graph_, preheader);
// Remove the cycle, replacing all uses. Even environment uses can consume the final
// value, since any first real use is outside the loop (although this may imply
// that deopting may look "ahead" a bit on the phi value).
ReplaceAllUses(phi, last, addsub);
RemoveFromCycle(phi); // removes environment uses too
RemoveFromCycle(addsub);
}마찬가지로 주석처럼 for (int i = 0; i < 10; i++, k++) { .... no k .... } return k; for문 내에서는 참조되지 않지만 예측 가능한 나중에 사용되는 값이 있을 경우 CanGenerateLastValue() == True, 선계산한 값으로 대체하는 GenerateLastValue() 코드 입니다.
다음 예제를 보겠습니다.
/// CHECK-START: int Main.closedFormInductionUp() loop_optimization (before)
/// CHECK-DAG: <<Phi1:i\d+>> Phi loop:<<Loop:B\d+>> outer_loop:none
/// CHECK-DAG: <<Phi2:i\d+>> Phi loop:<<Loop>> outer_loop:none
/// CHECK-DAG: Return [<<Phi1>>] loop:none
//
/// CHECK-START: int Main.closedFormInductionUp() loop_optimization (after)
/// CHECK-NOT: Phi loop:B\d+ outer_loop:none
/// CHECK-DAG: Return loop:none
static int closedFormInductionUp() {
int closed = 12345;
for (int i = 0; i < 10; i++) {
closed += 5;
}
return closed; // only needs last value
}위 예제에서 closed는 i 와 무관하게 계산 가능합니다.
그러므로 해당 Javacode는 원래는 for-loop문의 결과를 반환(PHI1) 하게 되어 있지만,
최적화 할 수 있습니다.
// value 계산
InductionVarRange::Value InductionVarRange::GetLinear(HInductionVarAnalysis::InductionInfo* info,
HInductionVarAnalysis::InductionInfo* trip,
bool in_body,
bool is_min) const {
// Detect common situation where an offset inside the trip-count cancels out during range
// analysis (finding max a * (TC - 1) + OFFSET for a == 1 and TC = UPPER - OFFSET or finding
// min a * (TC - 1) + OFFSET for a == -1 and TC = OFFSET - UPPER) to avoid losing information
// with intermediate results that only incorporate single instructions.
if (trip != nullptr) { ... }
// General rule of linear induction a * i + b, for normalized 0 <= i < TC.
return AddValue(GetMul(info->op_a, trip, trip, in_body, is_min),
GetVal(info->op_b, trip, in_body, is_min));
}
// intruction 교체
case HInductionVarAnalysis::kLinear: {
// Linear induction a * i + b, for normalized 0 <= i < TC. For ranges, this should
// be restricted to a unit stride to avoid arithmetic wrap-around situations that
// are harder to guard against. For a last value, requesting min/max based on any
// stride yields right value.
int64_t stride_value = 0;
if (IsConstant(info->op_a, kExact, &stride_value)) {
const bool is_min_a = stride_value >= 0 ? is_min : !is_min;
if (GenerateCode(trip, trip, graph, block, &opa, in_body, is_min_a) &&
GenerateCode(info->op_b, trip, graph, block, &opb, in_body, is_min)) {
if (graph != nullptr) {
HInstruction* oper;
if (stride_value == 1) {
oper = new (graph->GetArena()) HAdd(type, opa, opb);
} else if (stride_value == -1) {
oper = new (graph->GetArena()) HSub(type, opb, opa);
} else {
HInstruction* mul = new (graph->GetArena()) HMul(
type, graph->GetIntConstant(stride_value), opa);
oper = new (graph->GetArena()) HAdd(type, Insert(block, mul), opb);
}
*result = Insert(block, oper);
}
return true;
}
}
break;
}for-loop 의 range(0..i) * constant 5 를 preblock에 추가하는 것으로
closed += 5 연산을 i-1 번 줄일 수 있게 된다.
이것이 끝인데, 평소 생각하시던 최적화와 비교하면 어떠실런지 모르겠습니다.
최적화는 수학이 많이 적용되는 기법인데 이런 최적화(?) 도 존재한다고 생각하면
좀더 친숙하게 느껴지지 않을까 합니다!
'Knowledge > Compiler' 카테고리의 다른 글
| LLVM Obfuscator] Control Flow Graph Flattening (0) | 2021.02.15 |
|---|---|
| LLVM Obfuscator] Call (0) | 2021.02.13 |
| LLVM - Why should we know this? (0) | 2020.07.19 |
| GCC compile (0) | 2018.04.09 |
| gcc 사용 중에 버그를 발견했을때 report 하는 방법. (0) | 2018.04.09 |


